BGP¶
BGP stands for Border Gateway Protocol. The latest BGP version is 4. BGP-4 is one of the Exterior Gateway Protocols and the de facto standard interdomain routing protocol. BGP-4 is described in RFC 1771 and updated by RFC 4271. RFC 2858 adds multiprotocol support to BGP-4.
Starting BGP¶
The default configuration file of bgpd is bgpd.conf. bgpd searches
the current directory first, followed by /etc/frr/bgpd.conf. All of
bgpd's commands must be configured in bgpd.conf when the integrated
config is not being used.
bgpd specific invocation options are described below. Common options may also be specified (Common Invocation Options).
-
-p,--bgp_port<port>¶ Set the bgp protocol's port number. When port number is 0, that means do not listen bgp port.
-
-l,--listenon¶ Specify a specific IP address for bgpd to listen on, rather than its default of
0.0.0.0/::. This can be useful to constrain bgpd to an internal address, or to run multiple bgpd processes on one host.
Basic Concepts¶
Autonomous Systems¶
From RFC 1930:
An AS is a connected group of one or more IP prefixes run by one or more network operators which has a SINGLE and CLEARLY DEFINED routing policy.
Each AS has an identifying number associated with it called an ASN. This is a two octet value ranging in value from 1 to 65535. The AS numbers 64512 through 65535 are defined as private AS numbers. Private AS numbers must not be advertised on the global Internet.
The ASN is one of the essential elements of BGP. BGP is a distance vector routing protocol, and the AS-Path framework provides distance vector metric and loop detection to BGP.
See also
Address Families¶
Multiprotocol extensions enable BGP to carry routing information for multiple network layer protocols. BGP supports an Address Family Identifier (AFI) for IPv4 and IPv6. Support is also provided for multiple sets of per-AFI information via the BGP Subsequent Address Family Identifier (SAFI). FRR supports SAFIs for unicast information, labeled information (RFC 3107 and RFC 8277), and Layer 3 VPN information (RFC 4364 and RFC 4659).
Route Selection¶
The route selection process used by FRR's BGP implementation uses the following decision criterion, starting at the top of the list and going towards the bottom until one of the factors can be used.
Weight check
Prefer higher local weight routes to lower routes.
Local preference check
Prefer higher local preference routes to lower.
Local route check
Prefer local routes (statics, aggregates, redistributed) to received routes.
AS path length check
Prefer shortest hop-count AS_PATHs.
Origin check
Prefer the lowest origin type route. That is, prefer IGP origin routes to EGP, to Incomplete routes.
MED check
Where routes with a MED were received from the same AS, prefer the route with the lowest MED. Multi-Exit Discriminator.
External check
Prefer the route received from an external, eBGP peer over routes received from other types of peers.
IGP cost check
Prefer the route with the lower IGP cost.
Multi-path check
If multi-pathing is enabled, then check whether the routes not yet distinguished in preference may be considered equal. If
bgp bestpath as-path multipath-relaxis set, all such routes are considered equal, otherwise routes received via iBGP with identical AS_PATHs or routes received from eBGP neighbours in the same AS are considered equal.Already-selected external check
Where both routes were received from eBGP peers, then prefer the route which is already selected. Note that this check is not applied if
bgp bestpath compare-routeridis configured. This check can prevent some cases of oscillation.Router-ID check
Prefer the route with the lowest router-ID. If the route has an ORIGINATOR_ID attribute, through iBGP reflection, then that router ID is used, otherwise the router-ID of the peer the route was received from is used.
Cluster-List length check
The route with the shortest cluster-list length is used. The cluster-list reflects the iBGP reflection path the route has taken.
Peer address
Prefer the route received from the peer with the higher transport layer address, as a last-resort tie-breaker.
Capability Negotiation¶
When adding IPv6 routing information exchange feature to BGP. There were some proposals. IETF IDR adopted a proposal called Multiprotocol Extension for BGP. The specification is described in RFC 2283. The protocol does not define new protocols. It defines new attributes to existing BGP. When it is used exchanging IPv6 routing information it is called BGP-4+. When it is used for exchanging multicast routing information it is called MBGP.
bgpd supports Multiprotocol Extension for BGP. So if a remote peer supports the protocol, bgpd can exchange IPv6 and/or multicast routing information.
Traditional BGP did not have the feature to detect a remote peer's capabilities, e.g. whether it can handle prefix types other than IPv4 unicast routes. This was a big problem using Multiprotocol Extension for BGP in an operational network. RFC 2842 adopted a feature called Capability Negotiation. bgpd use this Capability Negotiation to detect the remote peer's capabilities. If a peer is only configured as an IPv4 unicast neighbor, bgpd does not send these Capability Negotiation packets (at least not unless other optional BGP features require capability negotiation).
By default, FRR will bring up peering with minimal common capability for the both sides. For example, if the local router has unicast and multicast capabilities and the remote router only has unicast capability the local router will establish the connection with unicast only capability. When there are no common capabilities, FRR sends Unsupported Capability error and then resets the connection.
BGP Router Configuration¶
ASN and Router ID¶
First of all you must configure BGP router with the router bgp ASN
command. The AS number is an identifier for the autonomous system. The BGP
protocol uses the AS number for detecting whether the BGP connection is
internal or external.
-
router bgp ASN¶ Enable a BGP protocol process with the specified ASN. After this statement you can input any BGP Commands.
-
no router bgp ASN¶ Destroy a BGP protocol process with the specified ASN.
-
bgp router-id A.B.C.D¶ This command specifies the router-ID. If bgpd connects to zebra it gets interface and address information. In that case default router ID value is selected as the largest IP Address of the interfaces. When router zebra is not enabled bgpd can't get interface information so router-id is set to 0.0.0.0. So please set router-id by hand.
Multiple Autonomous Systems¶
FRR's BGP implementation is capable of running multiple autonomous systems at once. Each configured AS corresponds to a Virtual Routing and Forwarding. In the past, to get the same functionality the network administrator had to run a new bgpd process; using VRFs allows multiple autonomous systems to be handled in a single process.
When using multiple autonomous systems, all router config blocks after the first one must specify a VRF to be the target of BGP's route selection. This VRF must be unique within respect to all other VRFs being used for the same purpose, i.e. two different autonomous systems cannot use the same VRF. However, the same AS can be used with different VRFs.
Note
The separated nature of VRFs makes it possible to peer a single bgpd process to itself, on one machine. Note that this can be done fully within BGP without a corresponding VRF in the kernel or Zebra, which enables some practical use cases such as route reflectors and route servers.
Configuration of additional autonomous systems, or of a router that targets a specific VRF, is accomplished with the following command:
-
router bgp ASN vrf VRFNAME¶ VRFNAMEis matched against VRFs configured in the kernel. Whenvrf VRFNAMEis not specified, the BGP protocol process belongs to the default VRF.
An example configuration with multiple autonomous systems might look like this:
router bgp 1
neighbor 10.0.0.1 remote-as 20
neighbor 10.0.0.2 remote-as 30
!
router bgp 2 vrf blue
neighbor 10.0.0.3 remote-as 40
neighbor 10.0.0.4 remote-as 50
!
router bgp 3 vrf red
neighbor 10.0.0.5 remote-as 60
neighbor 10.0.0.6 remote-as 70
...
See also
See also
Views¶
In addition to supporting multiple autonomous systems, FRR's BGP implementation also supports views.
BGP views are almost the same as normal BGP processes, except that routes selected by BGP are not installed into the kernel routing table. Each BGP view provides an independent set of routing information which is only distributed via BGP. Multiple views can be supported, and BGP view information is always independent from other routing protocols and Zebra/kernel routes. BGP views use the core instance (i.e., default VRF) for communication with peers.
-
router bgp AS-NUMBER view NAME¶ Make a new BGP view. You can use an arbitrary word for the
NAME. Routes selected by the view are not installed into the kernel routing table.With this command, you can setup Route Server like below.
! router bgp 1 view 1 neighbor 10.0.0.1 remote-as 2 neighbor 10.0.0.2 remote-as 3 ! router bgp 2 view 2 neighbor 10.0.0.3 remote-as 4 neighbor 10.0.0.4 remote-as 5
-
show [ip] bgp view NAME¶ Display the routing table of BGP view
NAME.
Route Selection¶
-
bgp bestpath as-path confed¶ This command specifies that the length of confederation path sets and sequences should should be taken into account during the BGP best path decision process.
-
bgp bestpath as-path multipath-relax¶ This command specifies that BGP decision process should consider paths of equal AS_PATH length candidates for multipath computation. Without the knob, the entire AS_PATH must match for multipath computation.
-
bgp bestpath compare-routerid¶ Ensure that when comparing routes where both are equal on most metrics, including local-pref, AS_PATH length, IGP cost, MED, that the tie is broken based on router-ID.
If this option is enabled, then the already-selected check, where already selected eBGP routes are preferred, is skipped.
If a route has an ORIGINATOR_ID attribute because it has been reflected, that ORIGINATOR_ID will be used. Otherwise, the router-ID of the peer the route was received from will be used.
The advantage of this is that the route-selection (at this point) will be more deterministic. The disadvantage is that a few or even one lowest-ID router may attract all traffic to otherwise-equal paths because of this check. It may increase the possibility of MED or IGP oscillation, unless other measures were taken to avoid these. The exact behaviour will be sensitive to the iBGP and reflection topology.
Administrative Distance Metrics¶
-
distance bgp (1-255) (1-255) (1-255)¶ This command change distance value of BGP. The arguments are the distance values for for external routes, internal routes and local routes respectively.
-
distance (1-255) A.B.C.D/M¶
-
distance (1-255) A.B.C.D/M WORD¶ Sets the administrative distance for a particular route.
Require policy on EBGP¶
-
[no] bgp ebgp-requires-policy¶ This command requires incoming and outgoing filters to be applied for eBGP sessions. Without the incoming filter, no routes will be accepted. Without the outgoing filter, no routes will be announced.
Route Flap Dampening¶
-
bgp dampening (1-45) (1-20000) (1-20000) (1-255)¶ This command enables BGP route-flap dampening and specifies dampening parameters.
- half-life
- Half-life time for the penalty
- reuse-threshold
- Value to start reusing a route
- suppress-threshold
- Value to start suppressing a route
- max-suppress
- Maximum duration to suppress a stable route
The route-flap damping algorithm is compatible with RFC 2439. The use of this command is not recommended nowadays.
At the moment, route-flap dampening is not working per VRF and is working only for IPv4 unicast and multicast.
Multi-Exit Discriminator¶
The BGP MED attribute has properties which can cause subtle convergence problems in BGP. These properties and problems have proven to be hard to understand, at least historically, and may still not be widely understood. The following attempts to collect together and present what is known about MED, to help operators and FRR users in designing and configuring their networks.
The BGP MED attribute is intended to allow one AS to indicate its preferences for its ingress points to another AS. The MED attribute will not be propagated on to another AS by the receiving AS - it is 'non-transitive' in the BGP sense.
E.g., if AS X and AS Y have 2 different BGP peering points, then AS X might set a MED of 100 on routes advertised at one and a MED of 200 at the other. When AS Y selects between otherwise equal routes to or via AS X, AS Y should prefer to take the path via the lower MED peering of 100 with AS X. Setting the MED allows an AS to influence the routing taken to it within another, neighbouring AS.
In this use of MED it is not really meaningful to compare the MED value on routes where the next AS on the paths differs. E.g., if AS Y also had a route for some destination via AS Z in addition to the routes from AS X, and AS Z had also set a MED, it wouldn't make sense for AS Y to compare AS Z's MED values to those of AS X. The MED values have been set by different administrators, with different frames of reference.
The default behaviour of BGP therefore is to not compare MED values across routes received from different neighbouring ASes. In FRR this is done by comparing the neighbouring, left-most AS in the received AS_PATHs of the routes and only comparing MED if those are the same.
Unfortunately, this behaviour of MED, of sometimes being compared across routes and sometimes not, depending on the properties of those other routes, means MED can cause the order of preference over all the routes to be undefined. That is, given routes A, B, and C, if A is preferred to B, and B is preferred to C, then a well-defined order should mean the preference is transitive (in the sense of orders [1]) and that A would be preferred to C.
However, when MED is involved this need not be the case. With MED it is possible that C is actually preferred over A. So A is preferred to B, B is preferred to C, but C is preferred to A. This can be true even where BGP defines a deterministic 'most preferred' route out of the full set of A,B,C. With MED, for any given set of routes there may be a deterministically preferred route, but there need not be any way to arrange them into any order of preference. With unmodified MED, the order of preference of routes literally becomes undefined.
That MED can induce non-transitive preferences over routes can cause issues. Firstly, it may be perceived to cause routing table churn locally at speakers; secondly, and more seriously, it may cause routing instability in iBGP topologies, where sets of speakers continually oscillate between different paths.
The first issue arises from how speakers often implement routing decisions. Though BGP defines a selection process that will deterministically select the same route as best at any given speaker, even with MED, that process requires evaluating all routes together. For performance and ease of implementation reasons, many implementations evaluate route preferences in a pair-wise fashion instead. Given there is no well-defined order when MED is involved, the best route that will be chosen becomes subject to implementation details, such as the order the routes are stored in. That may be (locally) non-deterministic, e.g.: it may be the order the routes were received in.
This indeterminism may be considered undesirable, though it need not cause problems. It may mean additional routing churn is perceived, as sometimes more updates may be produced than at other times in reaction to some event .
This first issue can be fixed with a more deterministic route selection that
ensures routes are ordered by the neighbouring AS during selection.
bgp deterministic-med. This may reduce the number of updates as routes
are received, and may in some cases reduce routing churn. Though, it could
equally deterministically produce the largest possible set of updates in
response to the most common sequence of received updates.
A deterministic order of evaluation tends to imply an additional overhead of sorting over any set of n routes to a destination. The implementation of deterministic MED in FRR scales significantly worse than most sorting algorithms at present, with the number of paths to a given destination. That number is often low enough to not cause any issues, but where there are many paths, the deterministic comparison may quickly become increasingly expensive in terms of CPU.
Deterministic local evaluation can not fix the second, more major, issue of MED however. Which is that the non-transitive preference of routes MED can cause may lead to routing instability or oscillation across multiple speakers in iBGP topologies. This can occur with full-mesh iBGP, but is particularly problematic in non-full-mesh iBGP topologies that further reduce the routing information known to each speaker. This has primarily been documented with iBGP route-reflection topologies. However, any route-hiding technologies potentially could also exacerbate oscillation with MED.
This second issue occurs where speakers each have only a subset of routes, and there are cycles in the preferences between different combinations of routes - as the undefined order of preference of MED allows - and the routes are distributed in a way that causes the BGP speakers to 'chase' those cycles. This can occur even if all speakers use a deterministic order of evaluation in route selection.
E.g., speaker 4 in AS A might receive a route from speaker 2 in AS X, and from speaker 3 in AS Y; while speaker 5 in AS A might receive that route from speaker 1 in AS Y. AS Y might set a MED of 200 at speaker 1, and 100 at speaker 3. I.e, using ASN:ID:MED to label the speakers:
.
/---------------\\
X:2------|--A:4-------A:5--|-Y:1:200
Y:3:100--|-/ |
\\---------------/
Assuming all other metrics are equal (AS_PATH, ORIGIN, 0 IGP costs), then based on the RFC4271 decision process speaker 4 will choose X:2 over Y:3:100, based on the lower ID of 2. Speaker 4 advertises X:2 to speaker 5. Speaker 5 will continue to prefer Y:1:200 based on the ID, and advertise this to speaker 4. Speaker 4 will now have the full set of routes, and the Y:1:200 it receives from 5 will beat X:2, but when speaker 4 compares Y:1:200 to Y:3:100 the MED check now becomes active as the ASes match, and now Y:3:100 is preferred. Speaker 4 therefore now advertises Y:3:100 to 5, which will also agrees that Y:3:100 is preferred to Y:1:200, and so withdraws the latter route from 4. Speaker 4 now has only X:2 and Y:3:100, and X:2 beats Y:3:100, and so speaker 4 implicitly updates its route to speaker 5 to X:2. Speaker 5 sees that Y:1:200 beats X:2 based on the ID, and advertises Y:1:200 to speaker 4, and the cycle continues.
The root cause is the lack of a clear order of preference caused by how MED sometimes is and sometimes is not compared, leading to this cycle in the preferences between the routes:
.
/---> X:2 ---beats---> Y:3:100 --\\
| |
| |
\\---beats--- Y:1:200 <---beats---/
This particular type of oscillation in full-mesh iBGP topologies can be
avoided by speakers preferring already selected, external routes rather than
choosing to update to new a route based on a post-MED metric (e.g. router-ID),
at the cost of a non-deterministic selection process. FRR implements this, as
do many other implementations, so long as it is not overridden by setting
bgp bestpath compare-routerid, and see also
Route Selection.
However, more complex and insidious cycles of oscillation are possible with iBGP route-reflection, which are not so easily avoided. These have been documented in various places. See, e.g.:
for concrete examples and further references.
There is as of this writing no known way to use MED for its original purpose; and reduce routing information in iBGP topologies; and be sure to avoid the instability problems of MED due the non-transitive routing preferences it can induce; in general on arbitrary networks.
There may be iBGP topology specific ways to reduce the instability risks, even while using MED, e.g.: by constraining the reflection topology and by tuning IGP costs between route-reflector clusters, see RFC 3345 for details. In the near future, the Add-Path extension to BGP may also solve MED oscillation while still allowing MED to be used as intended, by distributing "best-paths per neighbour AS". This would be at the cost of distributing at least as many routes to all speakers as a full-mesh iBGP would, if not more, while also imposing similar CPU overheads as the "Deterministic MED" feature at each Add-Path reflector.
More generally, the instability problems that MED can introduce on more complex, non-full-mesh, iBGP topologies may be avoided either by:
- Setting
bgp always-compare-med, however this allows MED to be compared across values set by different neighbour ASes, which may not produce coherent desirable results, of itself. - Effectively ignoring MED by setting MED to the same value (e.g.: 0) using
set metric METRICon all received routes, in combination with settingbgp always-compare-medon all speakers. This is the simplest and most performant way to avoid MED oscillation issues, where an AS is happy not to allow neighbours to inject this problematic metric.
As MED is evaluated after the AS_PATH length check, another possible use for MED is for intra-AS steering of routes with equal AS_PATH length, as an extension of the last case above. As MED is evaluated before IGP metric, this can allow cold-potato routing to be implemented to send traffic to preferred hand-offs with neighbours, rather than the closest hand-off according to the IGP metric.
Note that even if action is taken to address the MED non-transitivity issues, other oscillations may still be possible. E.g., on IGP cost if iBGP and IGP topologies are at cross-purposes with each other - see the Flavel and Roughan paper above for an example. Hence the guideline that the iBGP topology should follow the IGP topology.
-
bgp deterministic-med¶ Carry out route-selection in way that produces deterministic answers locally, even in the face of MED and the lack of a well-defined order of preference it can induce on routes. Without this option the preferred route with MED may be determined largely by the order that routes were received in.
Setting this option will have a performance cost that may be noticeable when there are many routes for each destination. Currently in FRR it is implemented in a way that scales poorly as the number of routes per destination increases.
The default is that this option is not set.
Note that there are other sources of indeterminism in the route selection process, specifically, the preference for older and already selected routes from eBGP peers, Route Selection.
-
bgp always-compare-med¶ Always compare the MED on routes, even when they were received from different neighbouring ASes. Setting this option makes the order of preference of routes more defined, and should eliminate MED induced oscillations.
If using this option, it may also be desirable to use
set metric METRICto set MED to 0 on routes received from external neighbours.This option can be used, together with
set metric METRICto use MED as an intra-AS metric to steer equal-length AS_PATH routes to, e.g., desired exit points.
Networks¶
-
network A.B.C.D/M¶ This command adds the announcement network.
router bgp 1 address-family ipv4 unicast network 10.0.0.0/8 exit-address-family
This configuration example says that network 10.0.0.0/8 will be announced to all neighbors. Some vendors' routers don't advertise routes if they aren't present in their IGP routing tables; bgpd doesn't care about IGP routes when announcing its routes.
-
no network A.B.C.D/M¶
Route Aggregation¶
Route Aggregation-IPv4 Address Family¶
-
aggregate-address A.B.C.D/M¶ This command specifies an aggregate address.
-
aggregate-address A.B.C.D/M route-map NAME¶ Apply a route-map for an aggregated prefix.
-
aggregate-address A.B.C.D/M as-set¶ This command specifies an aggregate address. Resulting routes include AS set.
-
aggregate-address A.B.C.D/M summary-only¶ This command specifies an aggregate address. Aggregated routes will not be announce.
-
no aggregate-address A.B.C.D/M¶ This command removes an aggregate address.
This configuration example setup the aggregate-address under ipv4 address-family.
router bgp 1 address-family ipv4 unicast aggregate-address 10.0.0.0/8 aggregate-address 20.0.0.0/8 as-set aggregate-address 40.0.0.0/8 summary-only aggregate-address 50.0.0.0/8 route-map aggr-rmap exit-address-family
Route Aggregation-IPv6 Address Family¶
-
aggregate-address X:X::X:X/M¶ This command specifies an aggregate address.
-
aggregate-address X:X::X:X/M route-map NAME¶ Apply a route-map for an aggregated prefix.
-
aggregate-address X:X::X:X/M as-set¶ This command specifies an aggregate address. Resulting routes include AS set.
-
aggregate-address X:X::X:X/M summary-only¶ This command specifies an aggregate address. Aggregated routes will not be announce.
-
no aggregate-address X:X::X:X/M¶ This command removes an aggregate address.
This configuration example setup the aggregate-address under ipv6 address-family.
router bgp 1 address-family ipv6 unicast aggregate-address 10::0/64 aggregate-address 20::0/64 as-set aggregate-address 40::0/64 summary-only aggregate-address 50::0/64 route-map aggr-rmap exit-address-family
Redistribution¶
-
redistribute kernel¶ Redistribute kernel route to BGP process.
-
redistribute static¶ Redistribute static route to BGP process.
-
redistribute connected¶ Redistribute connected route to BGP process.
-
redistribute rip¶ Redistribute RIP route to BGP process.
-
redistribute ospf¶ Redistribute OSPF route to BGP process.
-
redistribute vnc¶ Redistribute VNC routes to BGP process.
-
redistribute vnc-direct¶ Redistribute VNC direct (not via zebra) routes to BGP process.
-
update-delay MAX-DELAY¶
-
update-delay MAX-DELAY ESTABLISH-WAIT¶ This feature is used to enable read-only mode on BGP process restart or when BGP process is cleared using 'clear ip bgp *'. When applicable, read-only mode would begin as soon as the first peer reaches Established status and a timer for max-delay seconds is started.
During this mode BGP doesn't run any best-path or generate any updates to its peers. This mode continues until:
- All the configured peers, except the shutdown peers, have sent explicit EOR (End-Of-RIB) or an implicit-EOR. The first keep-alive after BGP has reached Established is considered an implicit-EOR. If the establish-wait optional value is given, then BGP will wait for peers to reach established from the beginning of the update-delay till the establish-wait period is over, i.e. the minimum set of established peers for which EOR is expected would be peers established during the establish-wait window, not necessarily all the configured neighbors.
- max-delay period is over.
On hitting any of the above two conditions, BGP resumes the decision process and generates updates to its peers.
Default max-delay is 0, i.e. the feature is off by default.
-
table-map ROUTE-MAP-NAME¶ This feature is used to apply a route-map on route updates from BGP to Zebra. All the applicable match operations are allowed, such as match on prefix, next-hop, communities, etc. Set operations for this attach-point are limited to metric and next-hop only. Any operation of this feature does not affect BGPs internal RIB.
Supported for ipv4 and ipv6 address families. It works on multi-paths as well, however, metric setting is based on the best-path only.
Peers¶
Defining Peers¶
-
neighbor PEER remote-as ASN¶ Creates a new neighbor whose remote-as is ASN. PEER can be an IPv4 address or an IPv6 address or an interface to use for the connection.
router bgp 1 neighbor 10.0.0.1 remote-as 2
In this case my router, in AS-1, is trying to peer with AS-2 at 10.0.0.1.
This command must be the first command used when configuring a neighbor. If the remote-as is not specified, bgpd will complain like this:
can't find neighbor 10.0.0.1
-
neighbor PEER remote-as internal¶ Create a peer as you would when you specify an ASN, except that if the peers ASN is different than mine as specified under the
router bgp ASNcommand the connection will be denied.
-
neighbor PEER remote-as external¶ Create a peer as you would when you specify an ASN, except that if the peers ASN is the same as mine as specified under the
router bgp ASNcommand the connection will be denied.
-
[no] bgp listen range <A.B.C.D/M|X:X::X:X/M> peer-group PGNAME¶ Accept connections from any peers in the specified prefix. Configuration from the specified peer-group is used to configure these peers.
Note
When using BGP listen ranges, if the associated peer group has TCP MD5 authentication configured, your kernel must support this on prefixes. On Linux, this support was added in kernel version 4.14. If your kernel does not support this feature you will get a warning in the log file, and the listen range will only accept connections from peers without MD5 configured.
Additionally, we have observed that when using this option at scale (several hundred peers) the kernel may hit its option memory limit. In this situation you will see error messages like:
bgpd: sockopt_tcp_signature: setsockopt(23): Cannot allocate memory
In this case you need to increase the value of the sysctl
net.core.optmem_max to allow the kernel to allocate the necessary option
memory.
Configuring Peers¶
-
[no] neighbor PEER shutdown¶ Shutdown the peer. We can delete the neighbor's configuration by
no neighbor PEER remote-as ASNbut all configuration of the neighbor will be deleted. When you want to preserve the configuration, but want to drop the BGP peer, use this syntax.
-
[no] neighbor PEER disable-connected-check¶ Allow peerings between directly connected eBGP peers using loopback addresses.
-
[no] neighbor PEER ebgp-multihop¶
-
[no] neighbor PEER description ...¶ Set description of the peer.
-
[no] neighbor PEER version VERSION¶ Set up the neighbor's BGP version. version can be 4, 4+ or 4-. BGP version 4 is the default value used for BGP peering. BGP version 4+ means that the neighbor supports Multiprotocol Extensions for BGP-4. BGP version 4- is similar but the neighbor speaks the old Internet-Draft revision 00's Multiprotocol Extensions for BGP-4. Some routing software is still using this version.
-
[no] neighbor PEER interface IFNAME¶ When you connect to a BGP peer over an IPv6 link-local address, you have to specify the IFNAME of the interface used for the connection. To specify IPv4 session addresses, see the
neighbor PEER update-sourcecommand below.This command is deprecated and may be removed in a future release. Its use should be avoided.
-
[no] neighbor PEER next-hop-self [all]¶ This command specifies an announced route's nexthop as being equivalent to the address of the bgp router if it is learned via eBGP. If the optional keyword all is specified the modification is done also for routes learned via iBGP.
-
[no] neighbor PEER update-source <IFNAME|ADDRESS>¶ Specify the IPv4 source address to use for the BGP session to this neighbour, may be specified as either an IPv4 address directly or as an interface name (in which case the zebra daemon MUST be running in order for bgpd to be able to retrieve interface state).
router bgp 64555 neighbor foo update-source 192.168.0.1 neighbor bar update-source lo0
-
[no] neighbor PEER default-originate¶ bgpd's default is to not announce the default route (0.0.0.0/0) even if it is in routing table. When you want to announce default routes to the peer, use this command.
-
neighbor PEER port PORT¶
-
neighbor PEER send-community¶
-
[no] neighbor PEER weight WEIGHT¶ This command specifies a default weight value for the neighbor's routes.
-
[no] neighbor PEER maximum-prefix NUMBER¶ Sets a maximum number of prefixes we can receive from a given peer. If this number is exceeded, the BGP session will be destroyed.
In practice, it is generally preferable to use a prefix-list to limit what prefixes are received from the peer instead of using this knob. Tearing down the BGP session when a limit is exceeded is far more destructive than merely rejecting undesired prefixes. The prefix-list method is also much more granular and offers much smarter matching criterion than number of received prefixes, making it more suited to implementing policy.
-
[no] neighbor PEER local-as AS-NUMBER [no-prepend] [replace-as]¶ Specify an alternate AS for this BGP process when interacting with the specified peer. With no modifiers, the specified local-as is prepended to the received AS_PATH when receiving routing updates from the peer, and prepended to the outgoing AS_PATH (after the process local AS) when transmitting local routes to the peer.
If the no-prepend attribute is specified, then the supplied local-as is not prepended to the received AS_PATH.
If the replace-as attribute is specified, then only the supplied local-as is prepended to the AS_PATH when transmitting local-route updates to this peer.
Note that replace-as can only be specified if no-prepend is.
This command is only allowed for eBGP peers.
-
[no] neighbor PEER ttl-security hops NUMBER¶ This command enforces Generalized TTL Security Mechanism (GTSM), as specified in RFC 5082. With this command, only neighbors that are the specified number of hops away will be allowed to become neighbors. This command is mutually exclusive with ebgp-multihop.
-
[no] neighbor PEER capability extended-nexthop¶ Allow bgp to negotiate the extended-nexthop capability with it's peer. If you are peering over a v6 LL address then this capability is turned on automatically. If you are peering over a v6 Global Address then turning on this command will allow BGP to install v4 routes with v6 nexthops if you do not have v4 configured on interfaces.
-
[no] bgp fast-external-failover¶ This command causes bgp to not take down ebgp peers immediately when a link flaps. bgp fast-external-failover is the default and will not be displayed as part of a show run. The no form of the command turns off this ability.
-
[no] bgp default ipv4-unicast¶ This command allows the user to specify that v4 peering is turned on by default or not. This command defaults to on and is not displayed. The no bgp default ipv4-unicast form of the command is displayed.
Peer Filtering¶
-
neighbor PEER distribute-list NAME [in|out]¶ This command specifies a distribute-list for the peer. direct is
inorout.
-
neighbor PEER prefix-list NAME [in|out]¶
-
neighbor PEER filter-list NAME [in|out]¶
-
neighbor PEER route-map NAME [in|out]¶ Apply a route-map on the neighbor. direct must be in or out.
-
bgp route-reflector allow-outbound-policy¶ By default, attribute modification via route-map policy out is not reflected on reflected routes. This option allows the modifications to be reflected as well. Once enabled, it affects all reflected routes.
Peer Groups¶
Peer groups are used to help improve scaling by generating the same update information to all members of a peer group. Note that this means that the routes generated by a member of a peer group will be sent back to that originating peer with the originator identifier attribute set to indicated the originating peer. All peers not associated with a specific peer group are treated as belonging to a default peer group, and will share updates.
-
neighbor WORD peer-group¶ This command defines a new peer group.
-
neighbor PEER peer-group PGNAME¶ This command bind specific peer to peer group WORD.
-
neighbor PEER solo¶ This command is used to indicate that routes advertised by the peer should not be reflected back to the peer. This command only is only meaningful when there is a single peer defined in the peer-group.
Capability Negotiation¶
-
neighbor PEER strict-capability-match¶
-
no neighbor PEER strict-capability-match¶ Strictly compares remote capabilities and local capabilities. If capabilities are different, send Unsupported Capability error then reset connection.
You may want to disable sending Capability Negotiation OPEN message optional parameter to the peer when remote peer does not implement Capability Negotiation. Please use dont-capability-negotiate command to disable the feature.
-
neighbor PEER dont-capability-negotiate¶
-
no neighbor PEER dont-capability-negotiate¶ Suppress sending Capability Negotiation as OPEN message optional parameter to the peer. This command only affects the peer is configured other than IPv4 unicast configuration.
When remote peer does not have capability negotiation feature, remote peer will not send any capabilities at all. In that case, bgp configures the peer with configured capabilities.
You may prefer locally configured capabilities more than the negotiated capabilities even though remote peer sends capabilities. If the peer is configured by override-capability, bgpd ignores received capabilities then override negotiated capabilities with configured values.
-
neighbor PEER override-capability¶
-
no neighbor PEER override-capability¶ Override the result of Capability Negotiation with local configuration. Ignore remote peer's capability value.
AS Path Access Lists¶
AS path access list is user defined AS path.
-
ip as-path access-list WORD permit|deny LINE¶ This command defines a new AS path access list.
-
no ip as-path access-list WORD¶
-
no ip as-path access-list WORD permit|deny LINE¶
Using AS Path in Route Map¶
-
[no] match as-path WORD¶ For a given as-path, WORD, match it on the BGP as-path given for the prefix and if it matches do normal route-map actions. The no form of the command removes this match from the route-map.
-
[no] set as-path prepend AS-PATH¶ Prepend the given string of AS numbers to the AS_PATH of the BGP path's NLRI. The no form of this command removes this set operation from the route-map.
-
[no] set as-path prepend last-as NUM¶ Prepend the existing last AS number (the leftmost ASN) to the AS_PATH. The no form of this command removes this set operation from the route-map.
Communities Attribute¶
The BGP communities attribute is widely used for implementing policy routing. Network operators can manipulate BGP communities attribute based on their network policy. BGP communities attribute is defined in RFC 1997 and RFC 1998. It is an optional transitive attribute, therefore local policy can travel through different autonomous system.
The communities attribute is a set of communities values. Each community value is 4 octet long. The following format is used to define the community value.
AS:VAL- This format represents 4 octet communities value.
ASis high order 2 octet in digit format.VALis low order 2 octet in digit format. This format is useful to define AS oriented policy value. For example,7675:80can be used when AS 7675 wants to pass local policy value 80 to neighboring peer. internetinternetrepresents well-known communities value 0.graceful-shutdowngraceful-shutdownrepresents well-known communities valueGRACEFUL_SHUTDOWN0xFFFF000065535:0. RFC 8326 implements the purpose Graceful BGP Session Shutdown to reduce the amount of lost traffic when taking BGP sessions down for maintenance. The use of the community needs to be supported from your peers side to actually have any effect.accept-ownaccept-ownrepresents well-known communities valueACCEPT_OWN0xFFFF000165535:1. RFC 7611 implements a way to signal to a router to accept routes with a local nexthop address. This can be the case when doing policing and having traffic having a nexthop located in another VRF but still local interface to the router. It is recommended to read the RFC for full details.route-filter-translated-v4route-filter-translated-v4represents well-known communities valueROUTE_FILTER_TRANSLATED_v40xFFFF000265535:2.route-filter-v4route-filter-v4represents well-known communities valueROUTE_FILTER_v40xFFFF000365535:3.route-filter-translated-v6route-filter-translated-v6represents well-known communities valueROUTE_FILTER_TRANSLATED_v60xFFFF000465535:4.route-filter-v6route-filter-v6represents well-known communities valueROUTE_FILTER_v60xFFFF000565535:5.llgr-stalellgr-stalerepresents well-known communities valueLLGR_STALE0xFFFF000665535:6. Assigned and intended only for use with routers supporting the Long-lived Graceful Restart Capability as described in [Draft-IETF-uttaro-idr-bgp-persistence]. Routers receiving routes with this community may (depending on implementation) choose allow to reject or modify routes on the presence or absence of this community.no-llgrno-llgrrepresents well-known communities valueNO_LLGR0xFFFF000765535:7. Assigned and intended only for use with routers supporting the Long-lived Graceful Restart Capability as described in [Draft-IETF-uttaro-idr-bgp-persistence]. Routers receiving routes with this community may (depending on implementation) choose allow to reject or modify routes on the presence or absence of this community.accept-own-nexthopaccept-own-nexthoprepresents well-known communities valueaccept-own-nexthop0xFFFF000865535:8. [Draft-IETF-agrewal-idr-accept-own-nexthop] describes how to tag and label VPN routes to be able to send traffic between VRFs via an internal layer 2 domain on the same PE device. Refer to [Draft-IETF-agrewal-idr-accept-own-nexthop] for full details.blackholeblackholerepresents well-known communities valueBLACKHOLE0xFFFF029A65535:666. RFC 7999 documents sending prefixes to EBGP peers and upstream for the purpose of blackholing traffic. Prefixes tagged with the this community should normally not be re-advertised from neighbors of the originating network. It is recommended upon receiving prefixes tagged with this community to addNO_EXPORTandNO_ADVERTISE.no-exportno-exportrepresents well-known communities valueNO_EXPORT0xFFFFFF01. All routes carry this value must not be advertised to outside a BGP confederation boundary. If neighboring BGP peer is part of BGP confederation, the peer is considered as inside a BGP confederation boundary, so the route will be announced to the peer.no-advertiseno-advertiserepresents well-known communities valueNO_ADVERTISE0xFFFFFF02. All routes carry this value must not be advertise to other BGP peers.local-ASlocal-ASrepresents well-known communities valueNO_EXPORT_SUBCONFED0xFFFFFF03. All routes carry this value must not be advertised to external BGP peers. Even if the neighboring router is part of confederation, it is considered as external BGP peer, so the route will not be announced to the peer.no-peerno-peerrepresents well-known communities valueNOPEER0xFFFFFF0465535:65284. RFC 3765 is used to communicate to another network how the originating network want the prefix propagated.
When the communities attribute is received duplicate community values in the attribute are ignored and value is sorted in numerical order.
| [Draft-IETF-uttaro-idr-bgp-persistence] | (1, 2) <https://tools.ietf.org/id/draft-uttaro-idr-bgp-persistence-04.txt> |
| [Draft-IETF-agrewal-idr-accept-own-nexthop] | (1, 2) <https://tools.ietf.org/id/draft-agrewal-idr-accept-own-nexthop-00.txt> |
Community Lists¶
Community lists are user defined lists of community attribute values. These lists can be used for matching or manipulating the communities attribute in UPDATE messages.
There are two types of community list:
- standard
- This type accepts an explicit value for the attribute.
- expanded
- This type accepts a regular expression. Because the regex must be interpreted on each use expanded community lists are slower than standard lists.
-
ip community-list standard NAME permit|deny COMMUNITY¶ This command defines a new standard community list.
COMMUNITYis communities value. TheCOMMUNITYis compiled into community structure. We can define multiple community list under same name. In that case match will happen user defined order. Once the community list matches to communities attribute in BGP updates it return permit or deny by the community list definition. When there is no matched entry, deny will be returned. WhenCOMMUNITYis empty it matches to any routes.
-
ip community-list expanded NAME permit|deny COMMUNITY¶ This command defines a new expanded community list.
COMMUNITYis a string expression of communities attribute.COMMUNITYcan be a regular expression (BGP Regular Expressions) to match the communities attribute in BGP updates. The expanded community is only used to filter, not set actions.
Deprecated since version 5.0: It is recommended to use the more explicit versions of this command.
-
ip community-list NAME permit|deny COMMUNITY¶ When the community list type is not specified, the community list type is automatically detected. If
COMMUNITYcan be compiled into communities attribute, the community list is defined as a standard community list. Otherwise it is defined as an expanded community list. This feature is left for backward compatibility. Use of this feature is not recommended.
-
no ip community-list [standard|expanded] NAME¶ Deletes the community list specified by
NAME. All community lists share the same namespace, so it's not necessary to specifystandardorexpanded; these modifiers are purely aesthetic.
-
show ip community-list [NAME]¶ Displays community list information. When
NAMEis specified the specified community list's information is shown.# show ip community-list Named Community standard list CLIST permit 7675:80 7675:100 no-export deny internet Named Community expanded list EXPAND permit : # show ip community-list CLIST Named Community standard list CLIST permit 7675:80 7675:100 no-export deny internet
Numbered Community Lists¶
When number is used for BGP community list name, the number has special meanings. Community list number in the range from 1 and 99 is standard community list. Community list number in the range from 100 to 199 is expanded community list. These community lists are called as numbered community lists. On the other hand normal community lists is called as named community lists.
-
ip community-list (1-99) permit|deny COMMUNITY¶ This command defines a new community list. The argument to (1-99) defines the list identifier.
-
ip community-list (100-199) permit|deny COMMUNITY¶ This command defines a new expanded community list. The argument to (100-199) defines the list identifier.
Using Communities in Route Maps¶
In Route Maps we can match on or set the BGP communities attribute. Using this feature network operator can implement their network policy based on BGP communities attribute.
The ollowing commands can be used in route maps:
-
match community WORD exact-match [exact-match]¶ This command perform match to BGP updates using community list WORD. When the one of BGP communities value match to the one of communities value in community list, it is match. When exact-match keyword is specified, match happen only when BGP updates have completely same communities value specified in the community list.
-
set community <none|COMMUNITY> additive¶ This command sets the community value in BGP updates. If the attribute is already configured, the newly provided value replaces the old one unless the
additivekeyword is specified, in which case the new value is appended to the existing value.If
noneis specified as the community value, the communities attribute is not sent.It is not possible to set an expanded community list.
-
set comm-list WORD delete¶ This command remove communities value from BGP communities attribute. The
wordis community list name. When BGP route's communities value matches to the community listword, the communities value is removed. When all of communities value is removed eventually, the BGP update's communities attribute is completely removed.
Example Configuration¶
The following configuration is exemplary of the most typical usage of BGP communities attribute. In the example, AS 7675 provides an upstream Internet connection to AS 100. When the following configuration exists in AS 7675, the network operator of AS 100 can set local preference in AS 7675 network by setting BGP communities attribute to the updates.
router bgp 7675
neighbor 192.168.0.1 remote-as 100
address-family ipv4 unicast
neighbor 192.168.0.1 route-map RMAP in
exit-address-family
!
ip community-list 70 permit 7675:70
ip community-list 70 deny
ip community-list 80 permit 7675:80
ip community-list 80 deny
ip community-list 90 permit 7675:90
ip community-list 90 deny
!
route-map RMAP permit 10
match community 70
set local-preference 70
!
route-map RMAP permit 20
match community 80
set local-preference 80
!
route-map RMAP permit 30
match community 90
set local-preference 90
The following configuration announces 10.0.0.0/8 from AS 100 to AS 7675.
The route has communities value 7675:80 so when above configuration exists
in AS 7675, the announced routes' local preference value will be set to 80.
router bgp 100
network 10.0.0.0/8
neighbor 192.168.0.2 remote-as 7675
address-family ipv4 unicast
neighbor 192.168.0.2 route-map RMAP out
exit-address-family
!
ip prefix-list PLIST permit 10.0.0.0/8
!
route-map RMAP permit 10
match ip address prefix-list PLIST
set community 7675:80
The following configuration is an example of BGP route filtering using
communities attribute. This configuration only permit BGP routes which has BGP
communities value 0:80 or 0:90. The network operator can set special
internal communities value at BGP border router, then limit the BGP route
announcements into the internal network.
router bgp 7675
neighbor 192.168.0.1 remote-as 100
address-family ipv4 unicast
neighbor 192.168.0.1 route-map RMAP in
exit-address-family
!
ip community-list 1 permit 0:80 0:90
!
route-map RMAP permit in
match community 1
The following example filters BGP routes which have a community value of
1:1. When there is no match community-list returns deny. To avoid
filtering all routes, a permit line is set at the end of the
community-list.
router bgp 7675
neighbor 192.168.0.1 remote-as 100
address-family ipv4 unicast
neighbor 192.168.0.1 route-map RMAP in
exit-address-family
!
ip community-list standard FILTER deny 1:1
ip community-list standard FILTER permit
!
route-map RMAP permit 10
match community FILTER
The communities value keyword internet has special meanings in standard
community lists. In the below example internet matches all BGP routes even
if the route does not have communities attribute at all. So community list
INTERNET is the same as FILTER in the previous example.
ip community-list standard INTERNET deny 1:1
ip community-list standard INTERNET permit internet
The following configuration is an example of communities value deletion. With
this configuration the community values 100:1 and 100:2 are removed
from BGP updates. For communities value deletion, only permit
community-list is used. deny community-list is ignored.
router bgp 7675
neighbor 192.168.0.1 remote-as 100
address-family ipv4 unicast
neighbor 192.168.0.1 route-map RMAP in
exit-address-family
!
ip community-list standard DEL permit 100:1 100:2
!
route-map RMAP permit 10
set comm-list DEL delete
Extended Communities Attribute¶
BGP extended communities attribute is introduced with MPLS VPN/BGP technology. MPLS VPN/BGP expands capability of network infrastructure to provide VPN functionality. At the same time it requires a new framework for policy routing. With BGP Extended Communities Attribute we can use Route Target or Site of Origin for implementing network policy for MPLS VPN/BGP.
BGP Extended Communities Attribute is similar to BGP Communities Attribute. It is an optional transitive attribute. BGP Extended Communities Attribute can carry multiple Extended Community value. Each Extended Community value is eight octet length.
BGP Extended Communities Attribute provides an extended range compared with BGP Communities Attribute. Adding to that there is a type field in each value to provides community space structure.
There are two format to define Extended Community value. One is AS based format the other is IP address based format.
AS:VAL- This is a format to define AS based Extended Community value.
ASpart is 2 octets Global Administrator subfield in Extended Community value.VALpart is 4 octets Local Administrator subfield.7675:100represents AS 7675 policy value 100. IP-Address:VAL- This is a format to define IP address based Extended Community value.
IP-Addresspart is 4 octets Global Administrator subfield.VALpart is 2 octets Local Administrator subfield.
Extended Community Lists¶
-
ip extcommunity-list standard NAME permit|deny EXTCOMMUNITY¶ This command defines a new standard extcommunity-list. extcommunity is extended communities value. The extcommunity is compiled into extended community structure. We can define multiple extcommunity-list under same name. In that case match will happen user defined order. Once the extcommunity-list matches to extended communities attribute in BGP updates it return permit or deny based upon the extcommunity-list definition. When there is no matched entry, deny will be returned. When extcommunity is empty it matches to any routes.
-
ip extcommunity-list expanded NAME permit|deny LINE¶ This command defines a new expanded extcommunity-list. line is a string expression of extended communities attribute. line can be a regular expression (BGP Regular Expressions) to match an extended communities attribute in BGP updates.
-
no ip extcommunity-list NAME¶
-
no ip extcommunity-list standard NAME¶
-
no ip extcommunity-list expanded NAME¶ These commands delete extended community lists specified by name. All of extended community lists shares a single name space. So extended community lists can be removed simply specifying the name.
-
show ip extcommunity-list¶
-
show ip extcommunity-list NAME¶ This command displays current extcommunity-list information. When name is specified the community list's information is shown.:
# show ip extcommunity-list
BGP Extended Communities in Route Map¶
-
match extcommunity WORD¶
-
set extcommunity rt EXTCOMMUNITY¶ This command set Route Target value.
-
set extcommunity soo EXTCOMMUNITY¶ This command set Site of Origin value.
Note that the extended expanded community is only used for match rule, not for set actions.
Large Communities Attribute¶
The BGP Large Communities attribute was introduced in Feb 2017 with RFC 8092.
The BGP Large Communities Attribute is similar to the BGP Communities Attribute
except that it has 3 components instead of two and each of which are 4 octets
in length. Large Communities bring additional functionality and convenience
over traditional communities, specifically the fact that the GLOBAL part
below is now 4 octets wide allowing seamless use in networks using 4-byte ASNs.
GLOBAL:LOCAL1:LOCAL2This is the format to define Large Community values. Referencing RFC 8195 the values are commonly referred to as follows:
- The
GLOBALpart is a 4 octet Global Administrator field, commonly used as the operators AS number. - The
LOCAL1part is a 4 octet Local Data Part 1 subfield referred to as a function. - The
LOCAL2part is a 4 octet Local Data Part 2 field and referred to as the parameter subfield.
As an example,
65551:1:10represents AS 65551 function 1 and parameter 10. The referenced RFC above gives some guidelines on recommended usage.- The
Large Community Lists¶
Two types of large community lists are supported, namely standard and expanded.
-
ip large-community-list standard NAME permit|deny LARGE-COMMUNITY¶ This command defines a new standard large-community-list. large-community is the Large Community value. We can add multiple large communities under same name. In that case the match will happen in the user defined order. Once the large-community-list matches the Large Communities attribute in BGP updates it will return permit or deny based upon the large-community-list definition. When there is no matched entry, a deny will be returned. When large-community is empty it matches any routes.
-
ip large-community-list expanded NAME permit|deny LINE¶ This command defines a new expanded large-community-list. Where line is a string matching expression, it will be compared to the entire Large Communities attribute as a string, with each large-community in order from lowest to highest. line can also be a regular expression which matches this Large Community attribute.
-
no ip large-community-list NAME¶
-
no ip large-community-list standard NAME¶
-
no ip large-community-list expanded NAME¶ These commands delete Large Community lists specified by name. All Large Community lists share a single namespace. This means Large Community lists can be removed by simply specifying the name.
-
show ip large-community-list¶
-
show ip large-community-list NAME¶ This command display current large-community-list information. When name is specified the community list information is shown.
-
show ip bgp large-community-info¶ This command displays the current large communities in use.
Large Communities in Route Map¶
-
match large-community LINE [exact-match]¶ Where line can be a simple string to match, or a regular expression. It is very important to note that this match occurs on the entire large-community string as a whole, where each large-community is ordered from lowest to highest. When exact-match keyword is specified, match happen only when BGP updates have completely same large communities value specified in the large community list.
-
set large-community LARGE-COMMUNITY¶
-
set large-community LARGE-COMMUNITY LARGE-COMMUNITY¶
-
set large-community LARGE-COMMUNITY additive¶ These commands are used for setting large-community values. The first command will overwrite any large-communities currently present. The second specifies two large-communities, which overwrites the current large-community list. The third will add a large-community value without overwriting other values. Multiple large-community values can be specified.
Note that the large expanded community is only used for match rule, not for set actions.
L3VPN VRFs¶
bgpd supports L3VPN VRFs for IPv4 RFC 4364 and IPv6 RFC 4659. L3VPN routes, and their associated VRF MPLS labels, can be distributed to VPN SAFI neighbors in the default, i.e., non VRF, BGP instance. VRF MPLS labels are reached using core MPLS labels which are distributed using LDP or BGP labeled unicast. bgpd also supports inter-VRF route leaking.
VRF Route Leaking¶
BGP routes may be leaked (i.e. copied) between a unicast VRF RIB and the VPN
SAFI RIB of the default VRF for use in MPLS-based L3VPNs. Unicast routes may
also be leaked between any VRFs (including the unicast RIB of the default BGP
instanced). A shortcut syntax is also available for specifying leaking from one
VRF to another VRF using the default instance's VPN RIB as the intemediary. A
common application of the VRF-VRF feature is to connect a customer's private
routing domain to a provider's VPN service. Leaking is configured from the
point of view of an individual VRF: import refers to routes leaked from VPN
to a unicast VRF, whereas export refers to routes leaked from a unicast VRF
to VPN.
Required parameters¶
Routes exported from a unicast VRF to the VPN RIB must be augmented by two parameters:
- an RD
- an RTLIST
Configuration for these exported routes must, at a minimum, specify these two parameters.
Routes imported from the VPN RIB to a unicast VRF are selected according to their RTLISTs. Routes whose RTLIST contains at least one route-target in common with the configured import RTLIST are leaked. Configuration for these imported routes must specify an RTLIST to be matched.
The RD, which carries no semantic value, is intended to make the route unique in the VPN RIB among all routes of its prefix that originate from all the customers and sites that are attached to the provider's VPN service. Accordingly, each site of each customer is typically assigned an RD that is unique across the entire provider network.
The RTLIST is a set of route-target extended community values whose purpose is to specify route-leaking policy. Typically, a customer is assigned a single route-target value for import and export to be used at all customer sites. This configuration specifies a simple topology wherein a customer has a single routing domain which is shared across all its sites. More complex routing topologies are possible through use of additional route-targets to augment the leaking of sets of routes in various ways.
When using the shortcut syntax for vrf-to-vrf leaking, the RD and RT are auto-derived.
General configuration¶
Configuration of route leaking between a unicast VRF RIB and the VPN SAFI RIB of the default VRF is accomplished via commands in the context of a VRF address-family:
-
rd vpn export AS:NN|IP:nn¶ Specifies the route distinguisher to be added to a route exported from the current unicast VRF to VPN.
-
no rd vpn export [AS:NN|IP:nn]¶ Deletes any previously-configured export route distinguisher.
-
rt vpn import|export|both RTLIST...¶ Specifies the route-target list to be attached to a route (export) or the route-target list to match against (import) when exporting/importing between the current unicast VRF and VPN.
The RTLIST is a space-separated list of route-targets, which are BGP extended community values as described in Extended Communities Attribute.
-
no rt vpn import|export|both [RTLIST...]¶ Deletes any previously-configured import or export route-target list.
-
label vpn export (0..1048575)|auto¶ Enables an MPLS label to be attached to a route exported from the current unicast VRF to VPN. If the value specified is
auto, the label value is automatically assigned from a pool maintained by the Zebra daemon. If Zebra is not running, or if this command is not configured, automatic label assignment will not complete, which will block corresponding route export.
-
no label vpn export [(0..1048575)|auto]¶ Deletes any previously-configured export label.
-
nexthop vpn export A.B.C.D|X:X::X:X¶ Specifies an optional nexthop value to be assigned to a route exported from the current unicast VRF to VPN. If left unspecified, the nexthop will be set to 0.0.0.0 or 0:0::0:0 (self).
-
no nexthop vpn export [A.B.C.D|X:X::X:X]¶ Deletes any previously-configured export nexthop.
-
route-map vpn import|export MAP¶ Specifies an optional route-map to be applied to routes imported or exported between the current unicast VRF and VPN.
-
no route-map vpn import|export [MAP]¶ Deletes any previously-configured import or export route-map.
-
import|export vpn¶ Enables import or export of routes between the current unicast VRF and VPN.
-
no import|export vpn¶ Disables import or export of routes between the current unicast VRF and VPN.
-
import vrf VRFNAME¶ Shortcut syntax for specifying automatic leaking from vrf VRFNAME to the current VRF using the VPN RIB as intermediary. The RD and RT are auto derived and should not be specified explicitly for either the source or destination VRF's.
This shortcut syntax mode is not compatible with the explicit import vpn and export vpn statements for the two VRF's involved. The CLI will disallow attempts to configure incompatible leaking modes.
-
no import vrf VRFNAME¶ Disables automatic leaking from vrf VRFNAME to the current VRF using the VPN RIB as intermediary.
Cisco Compatibility¶
FRR has commands that change some configuration syntax and default behavior to behave more closely to Cisco conventions. These are deprecated and will be removed in a future version of FRR.
Deprecated since version 5.0: Please transition to using the FRR specific syntax for your configuration.
-
bgp config-type cisco¶ Cisco compatible BGP configuration output.
When this configuration line is specified:
no synchronizationis displayed. This command does nothing and is for display purposes only.no auto-summaryis displayed.The
networkandaggregate-addressarguments are displayed as:A.B.C.D M.M.M.M FRR: network 10.0.0.0/8 Cisco: network 10.0.0.0 FRR: aggregate-address 192.168.0.0/24 Cisco: aggregate-address 192.168.0.0 255.255.255.0
Community attribute handling is also different. If no configuration is specified community attribute and extended community attribute are sent to the neighbor. If a user manually disables the feature, the community attribute is not sent to the neighbor. When
bgp config-type ciscois specified, the community attribute is not sent to the neighbor by default. To send the community attribute user has to specifyneighbor A.B.C.D send-communitylike so:! router bgp 1 neighbor 10.0.0.1 remote-as 1 address-family ipv4 unicast no neighbor 10.0.0.1 send-community exit-address-family ! router bgp 1 neighbor 10.0.0.1 remote-as 1 address-family ipv4 unicast neighbor 10.0.0.1 send-community exit-address-family !
Deprecated since version 5.0: Please transition to using the FRR specific syntax for your configuration.
-
bgp config-type zebra¶ FRR style BGP configuration. This is the default.
Debugging¶
-
show debug¶ Show all enabled debugs.
-
[no] debug bgp neighbor-events¶ Enable or disable debugging for neighbor events. This provides general information on BGP events such as peer connection / disconnection, session establishment / teardown, and capability negotiation.
-
[no] debug bgp updates¶ Enable or disable debugging for BGP updates. This provides information on BGP UPDATE messages transmitted and received between local and remote instances.
-
[no] debug bgp keepalives¶ Enable or disable debugging for BGP keepalives. This provides information on BGP KEEPALIVE messages transmitted and received between local and remote instances.
-
[no] debug bgp bestpath <A.B.C.D/M|X:X::X:X/M>¶ Enable or disable debugging for bestpath selection on the specified prefix.
-
[no] debug bgp nht¶ Enable or disable debugging of BGP nexthop tracking.
-
[no] debug bgp update-groups¶ Enable or disable debugging of dynamic update groups. This provides general information on group creation, deletion, join and prune events.
-
[no] debug bgp zebra¶ Enable or disable debugging of communications between bgpd and zebra.
Dumping Messages and Routing Tables¶
-
dump bgp all PATH [INTERVAL]¶
-
dump bgp all-et PATH [INTERVAL]¶
-
no dump bgp all [PATH] [INTERVAL]¶ Dump all BGP packet and events to path file. If interval is set, a new file will be created for echo interval of seconds. The path path can be set with date and time formatting (strftime). The type ‘all-et’ enables support for Extended Timestamp Header (Packet Binary Dump Format).
-
dump bgp updates PATH [INTERVAL]¶
-
dump bgp updates-et PATH [INTERVAL]¶
-
no dump bgp updates [PATH] [INTERVAL]¶ Dump only BGP updates messages to path file. If interval is set, a new file will be created for echo interval of seconds. The path path can be set with date and time formatting (strftime). The type ‘updates-et’ enables support for Extended Timestamp Header (Packet Binary Dump Format).
-
dump bgp routes-mrt PATH¶
-
dump bgp routes-mrt PATH INTERVAL¶
-
no dump bgp route-mrt [PATH] [INTERVAL]¶ Dump whole BGP routing table to path. This is heavy process. The path path can be set with date and time formatting (strftime). If interval is set, a new file will be created for echo interval of seconds.
Note: the interval variable can also be set using hours and minutes: 04h20m00.
Other BGP Commands¶
-
clear bgp *¶ Clear all peers.
-
clear bgp ipv4|ipv6 *¶ Clear all peers with this address-family activated.
-
clear bgp ipv4|ipv6 unicast *¶ Clear all peers with this address-family and sub-address-family activated.
-
clear bgp ipv4|ipv6 PEER¶ Clear peers with address of X.X.X.X and this address-family activated.
-
clear bgp ipv4|ipv6 unicast PEER¶ Clear peer with address of X.X.X.X and this address-family and sub-address-family activated.
-
clear bgp ipv4|ipv6 PEER soft|in|out¶ Clear peer using soft reconfiguration in this address-family.
-
clear bgp ipv4|ipv6 unicast PEER soft|in|out¶ Clear peer using soft reconfiguration in this address-family and sub-address-family.
Displaying BGP Information¶
The following four commands display the IPv6 and IPv4 routing tables, depending
on whether or not the ip keyword is used.
Actually, show ip bgp command was used on older Quagga routing
daemon project, while show bgp command is the new format. The choice
has been done to keep old format with IPv4 routing table, while new format
displays IPv6 routing table.
-
show ip bgp¶
-
show ip bgp A.B.C.D¶
-
show bgp¶
-
show bgp X:X::X:X¶ These commands display BGP routes. When no route is specified, the default is to display all BGP routes.
BGP table version is 0, local router ID is 10.1.1.1 Status codes: s suppressed, d damped, h history, * valid, > best, i - internal Origin codes: i - IGP, e - EGP, ? - incomplete Network Next Hop Metric LocPrf Weight Path \*> 1.1.1.1/32 0.0.0.0 0 32768 i Total number of prefixes 1
Some other commands provide additional options for filtering the output.
-
show [ip] bgp regexp LINE¶ This command displays BGP routes using AS path regular expression (BGP Regular Expressions).
-
show [ip] bgp summary¶ Show a bgp peer summary for the specified address family.
The old command structure show ip bgp may be removed in the future
and should no longer be used. In order to reach the other BGP routing tables
other than the IPv6 routing table given by show bgp, the new command
structure is extended with show bgp [afi] [safi].
-
show bgp [afi] [safi]¶
-
show bgp <ipv4|ipv6> <unicast|multicast|vpn|labeled-unicast>¶ These commands display BGP routes for the specific routing table indicated by the selected afi and the selected safi. If no afi and no safi value is given, the command falls back to the default IPv6 routing table
-
show bgp [afi] [safi] summary¶ Show a bgp peer summary for the specified address family, and subsequent address-family.
-
show bgp [afi] [safi] summary failed [json]¶ Show a bgp peer summary for peers that are not succesfully exchanging routes for the specified address family, and subsequent address-family.
-
show bgp [afi] [safi] neighbor [PEER]¶ This command shows information on a specific BGP peer of the relevant afi and safi selected.
-
show bgp [afi] [safi] dampening dampened-paths¶ Display paths suppressed due to dampening of the selected afi and safi selected.
-
show bgp [afi] [safi] dampening flap-statistics¶ Display flap statistics of routes of the selected afi and safi selected.
Displaying Routes by Community Attribute¶
The following commands allow displaying routes based on their community attribute.
-
show [ip] bgp <ipv4|ipv6> community¶
-
show [ip] bgp <ipv4|ipv6> community COMMUNITY¶
-
show [ip] bgp <ipv4|ipv6> community COMMUNITY exact-match¶ These commands display BGP routes which have the community attribute. attribute. When
COMMUNITYis specified, BGP routes that match that community are displayed. When exact-match is specified, it display only routes that have an exact match.
-
show [ip] bgp <ipv4|ipv6> community-list WORD¶
-
show [ip] bgp <ipv4|ipv6> community-list WORD exact-match¶ These commands display BGP routes for the address family specified that match the specified community list. When exact-match is specified, it displays only routes that have an exact match.
Displaying Routes by Large Community Attribute¶
The following commands allow displaying routes based on their large community attribute.
-
show [ip] bgp <ipv4|ipv6> large-community¶
-
show [ip] bgp <ipv4|ipv6> large-community LARGE-COMMUNITY¶
-
show [ip] bgp <ipv4|ipv6> large-community LARGE-COMMUNITY exact-match¶
-
show [ip] bgp <ipv4|ipv6> large-community LARGE-COMMUNITY json¶ These commands display BGP routes which have the large community attribute. attribute. When
LARGE-COMMUNITYis specified, BGP routes that match that large community are displayed. When exact-match is specified, it display only routes that have an exact match. When json is specified, it display routes in json format.
-
show [ip] bgp <ipv4|ipv6> large-community-list WORD¶
-
show [ip] bgp <ipv4|ipv6> large-community-list WORD exact-match¶
-
show [ip] bgp <ipv4|ipv6> large-community-list WORD json¶ These commands display BGP routes for the address family specified that match the specified large community list. When exact-match is specified, it displays only routes that have an exact match. When json is specified, it display routes in json format.
Displaying Routes by AS Path¶
-
show bgp ipv4|ipv6 regexp LINE¶ This commands displays BGP routes that matches a regular expression line (BGP Regular Expressions).
-
show [ip] bgp ipv4 vpn¶
-
show [ip] bgp ipv6 vpn¶ Print active IPV4 or IPV6 routes advertised via the VPN SAFI.
-
show bgp ipv4 vpn summary¶
-
show bgp ipv6 vpn summary¶ Print a summary of neighbor connections for the specified AFI/SAFI combination.
Route Reflector¶
BGP routers connected inside the same AS through BGP belong to an internal BGP session, or IBGP. In order to prevent routing table loops, IBGP does not advertise IBGP-learned routes to other routers in the same session. As such, IBGP requires a full mesh of all peers. For large networks, this quickly becomes unscalable. Introducing route reflectors removes the need for the full-mesh.
When route reflectors are configured, these will reflect the routes announced by the peers configured as clients. A route reflector client is configured with:
-
neighbor PEER route-reflector-client¶
-
no neighbor PEER route-reflector-client¶
To avoid single points of failure, multiple route reflectors can be configured.
A cluster is a collection of route reflectors and their clients, and is used by route reflectors to avoid looping.
-
bgp cluster-id A.B.C.D¶
Routing Policy¶
You can set different routing policy for a peer. For example, you can set different filter for a peer.
!
router bgp 1 view 1
neighbor 10.0.0.1 remote-as 2
address-family ipv4 unicast
neighbor 10.0.0.1 distribute-list 1 in
exit-address-family
!
router bgp 1 view 2
neighbor 10.0.0.1 remote-as 2
address-family ipv4 unicast
neighbor 10.0.0.1 distribute-list 2 in
exit-address-family
This means BGP update from a peer 10.0.0.1 goes to both BGP view 1 and view 2. When the update is inserted into view 1, distribute-list 1 is applied. On the other hand, when the update is inserted into view 2, distribute-list 2 is applied.
BGP Regular Expressions¶
BGP regular expressions are based on POSIX 1003.2 regular expressions. The following description is just a quick subset of the POSIX regular expressions.
- .*
- Matches any single character.
- *
- Matches 0 or more occurrences of pattern.
- +
- Matches 1 or more occurrences of pattern.
- ?
- Match 0 or 1 occurrences of pattern.
- ^
- Matches the beginning of the line.
- $
- Matches the end of the line.
- _
- The
_character has special meanings in BGP regular expressions. It matches to space and comma , and AS set delimiter{and}and AS confederation delimiter(and). And it also matches to the beginning of the line and the end of the line. So_can be used for AS value boundaries match. This character technically evaluates to(^|[,{}()]|$).
Miscellaneous Configuration Examples¶
Example of a session to an upstream, advertising only one prefix to it.
router bgp 64512
bgp router-id 10.236.87.1
neighbor upstream peer-group
neighbor upstream remote-as 64515
neighbor upstream capability dynamic
neighbor 10.1.1.1 peer-group upstream
neighbor 10.1.1.1 description ACME ISP
address-family ipv4 unicast
network 10.236.87.0/24
neighbor upstream prefix-list pl-allowed-adv out
exit-address-family
!
ip prefix-list pl-allowed-adv seq 5 permit 82.195.133.0/25
ip prefix-list pl-allowed-adv seq 10 deny any
A more complex example including upstream, peer and customer sessions advertising global prefixes and NO_EXPORT prefixes and providing actions for customer routes based on community values. Extensive use is made of route-maps and the 'call' feature to support selective advertising of prefixes. This example is intended as guidance only, it has NOT been tested and almost certainly contains silly mistakes, if not serious flaws.
router bgp 64512
bgp router-id 10.236.87.1
neighbor upstream capability dynamic
neighbor cust capability dynamic
neighbor peer capability dynamic
neighbor 10.1.1.1 remote-as 64515
neighbor 10.1.1.1 peer-group upstream
neighbor 10.2.1.1 remote-as 64516
neighbor 10.2.1.1 peer-group upstream
neighbor 10.3.1.1 remote-as 64517
neighbor 10.3.1.1 peer-group cust-default
neighbor 10.3.1.1 description customer1
neighbor 10.4.1.1 remote-as 64518
neighbor 10.4.1.1 peer-group cust
neighbor 10.4.1.1 description customer2
neighbor 10.5.1.1 remote-as 64519
neighbor 10.5.1.1 peer-group peer
neighbor 10.5.1.1 description peer AS 1
neighbor 10.6.1.1 remote-as 64520
neighbor 10.6.1.1 peer-group peer
neighbor 10.6.1.1 description peer AS 2
address-family ipv4 unicast
network 10.123.456.0/24
network 10.123.456.128/25 route-map rm-no-export
neighbor upstream route-map rm-upstream-out out
neighbor cust route-map rm-cust-in in
neighbor cust route-map rm-cust-out out
neighbor cust send-community both
neighbor peer route-map rm-peer-in in
neighbor peer route-map rm-peer-out out
neighbor peer send-community both
neighbor 10.3.1.1 prefix-list pl-cust1-network in
neighbor 10.4.1.1 prefix-list pl-cust2-network in
neighbor 10.5.1.1 prefix-list pl-peer1-network in
neighbor 10.6.1.1 prefix-list pl-peer2-network in
exit-address-family
!
ip prefix-list pl-default permit 0.0.0.0/0
!
ip prefix-list pl-upstream-peers permit 10.1.1.1/32
ip prefix-list pl-upstream-peers permit 10.2.1.1/32
!
ip prefix-list pl-cust1-network permit 10.3.1.0/24
ip prefix-list pl-cust1-network permit 10.3.2.0/24
!
ip prefix-list pl-cust2-network permit 10.4.1.0/24
!
ip prefix-list pl-peer1-network permit 10.5.1.0/24
ip prefix-list pl-peer1-network permit 10.5.2.0/24
ip prefix-list pl-peer1-network permit 192.168.0.0/24
!
ip prefix-list pl-peer2-network permit 10.6.1.0/24
ip prefix-list pl-peer2-network permit 10.6.2.0/24
ip prefix-list pl-peer2-network permit 192.168.1.0/24
ip prefix-list pl-peer2-network permit 192.168.2.0/24
ip prefix-list pl-peer2-network permit 172.16.1/24
!
ip as-path access-list asp-own-as permit ^$
ip as-path access-list asp-own-as permit _64512_
!
! #################################################################
! Match communities we provide actions for, on routes receives from
! customers. Communities values of <our-ASN>:X, with X, have actions:
!
! 100 - blackhole the prefix
! 200 - set no_export
! 300 - advertise only to other customers
! 400 - advertise only to upstreams
! 500 - set no_export when advertising to upstreams
! 2X00 - set local_preference to X00
!
! blackhole the prefix of the route
ip community-list standard cm-blackhole permit 64512:100
!
! set no-export community before advertising
ip community-list standard cm-set-no-export permit 64512:200
!
! advertise only to other customers
ip community-list standard cm-cust-only permit 64512:300
!
! advertise only to upstreams
ip community-list standard cm-upstream-only permit 64512:400
!
! advertise to upstreams with no-export
ip community-list standard cm-upstream-noexport permit 64512:500
!
! set local-pref to least significant 3 digits of the community
ip community-list standard cm-prefmod-100 permit 64512:2100
ip community-list standard cm-prefmod-200 permit 64512:2200
ip community-list standard cm-prefmod-300 permit 64512:2300
ip community-list standard cm-prefmod-400 permit 64512:2400
ip community-list expanded cme-prefmod-range permit 64512:2...
!
! Informational communities
!
! 3000 - learned from upstream
! 3100 - learned from customer
! 3200 - learned from peer
!
ip community-list standard cm-learnt-upstream permit 64512:3000
ip community-list standard cm-learnt-cust permit 64512:3100
ip community-list standard cm-learnt-peer permit 64512:3200
!
! ###################################################################
! Utility route-maps
!
! These utility route-maps generally should not used to permit/deny
! routes, i.e. they do not have meaning as filters, and hence probably
! should be used with 'on-match next'. These all finish with an empty
! permit entry so as not interfere with processing in the caller.
!
route-map rm-no-export permit 10
set community additive no-export
route-map rm-no-export permit 20
!
route-map rm-blackhole permit 10
description blackhole, up-pref and ensure it cannot escape this AS
set ip next-hop 127.0.0.1
set local-preference 10
set community additive no-export
route-map rm-blackhole permit 20
!
! Set local-pref as requested
route-map rm-prefmod permit 10
match community cm-prefmod-100
set local-preference 100
route-map rm-prefmod permit 20
match community cm-prefmod-200
set local-preference 200
route-map rm-prefmod permit 30
match community cm-prefmod-300
set local-preference 300
route-map rm-prefmod permit 40
match community cm-prefmod-400
set local-preference 400
route-map rm-prefmod permit 50
!
! Community actions to take on receipt of route.
route-map rm-community-in permit 10
description check for blackholing, no point continuing if it matches.
match community cm-blackhole
call rm-blackhole
route-map rm-community-in permit 20
match community cm-set-no-export
call rm-no-export
on-match next
route-map rm-community-in permit 30
match community cme-prefmod-range
call rm-prefmod
route-map rm-community-in permit 40
!
! #####################################################################
! Community actions to take when advertising a route.
! These are filtering route-maps,
!
! Deny customer routes to upstream with cust-only set.
route-map rm-community-filt-to-upstream deny 10
match community cm-learnt-cust
match community cm-cust-only
route-map rm-community-filt-to-upstream permit 20
!
! Deny customer routes to other customers with upstream-only set.
route-map rm-community-filt-to-cust deny 10
match community cm-learnt-cust
match community cm-upstream-only
route-map rm-community-filt-to-cust permit 20
!
! ###################################################################
! The top-level route-maps applied to sessions. Further entries could
! be added obviously..
!
! Customers
route-map rm-cust-in permit 10
call rm-community-in
on-match next
route-map rm-cust-in permit 20
set community additive 64512:3100
route-map rm-cust-in permit 30
!
route-map rm-cust-out permit 10
call rm-community-filt-to-cust
on-match next
route-map rm-cust-out permit 20
!
! Upstream transit ASes
route-map rm-upstream-out permit 10
description filter customer prefixes which are marked cust-only
call rm-community-filt-to-upstream
on-match next
route-map rm-upstream-out permit 20
description only customer routes are provided to upstreams/peers
match community cm-learnt-cust
!
! Peer ASes
! outbound policy is same as for upstream
route-map rm-peer-out permit 10
call rm-upstream-out
!
route-map rm-peer-in permit 10
set community additive 64512:3200
Example of how to set up a 6-Bone connection.
! bgpd configuration
! ==================
!
! MP-BGP configuration
!
router bgp 7675
bgp router-id 10.0.0.1
neighbor 3ffe:1cfa:0:2:2a0:c9ff:fe9e:f56 remote-as `as-number`
!
address-family ipv6
network 3ffe:506::/32
neighbor 3ffe:1cfa:0:2:2a0:c9ff:fe9e:f56 activate
neighbor 3ffe:1cfa:0:2:2a0:c9ff:fe9e:f56 route-map set-nexthop out
neighbor 3ffe:1cfa:0:2:2c0:4fff:fe68:a231 remote-as `as-number`
neighbor 3ffe:1cfa:0:2:2c0:4fff:fe68:a231 route-map set-nexthop out
exit-address-family
!
ipv6 access-list all permit any
!
! Set output nexthop address.
!
route-map set-nexthop permit 10
match ipv6 address all
set ipv6 nexthop global 3ffe:1cfa:0:2:2c0:4fff:fe68:a225
set ipv6 nexthop local fe80::2c0:4fff:fe68:a225
!
log file bgpd.log
!
Configuring FRR as a Route Server¶
The purpose of a Route Server is to centralize the peerings between BGP speakers. For example if we have an exchange point scenario with four BGP speakers, each of which maintaining a BGP peering with the other three (Full Mesh), we can convert it into a centralized scenario where each of the four establishes a single BGP peering against the Route Server (Route server and clients).
We will first describe briefly the Route Server model implemented by FRR. We will explain the commands that have been added for configuring that model. And finally we will show a full example of FRR configured as Route Server.
Description of the Route Server model¶
First we are going to describe the normal processing that BGP announcements suffer inside a standard BGP speaker, as shown in Announcement processing inside a 'normal' BGP speaker, it consists of three steps:
- When an announcement is received from some peer, the In filters configured for that peer are applied to the announcement. These filters can reject the announcement, accept it unmodified, or accept it with some of its attributes modified.
- The announcements that pass the In filters go into the Best Path Selection process, where they are compared to other announcements referred to the same destination that have been received from different peers (in case such other announcements exist). For each different destination, the announcement which is selected as the best is inserted into the BGP speaker's Loc-RIB.
- The routes which are inserted in the Loc-RIB are considered for announcement to all the peers (except the one from which the route came). This is done by passing the routes in the Loc-RIB through the Out filters corresponding to each peer. These filters can reject the route, accept it unmodified, or accept it with some of its attributes modified. Those routes which are accepted by the Out filters of a peer are announced to that peer.
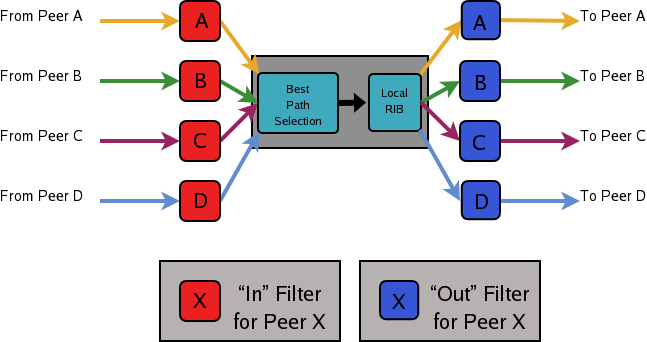
Announcement processing inside a 'normal' BGP speaker
Full Mesh
Route server and clients
Of course we want that the routing tables obtained in each of the routers are the same when using the route server than when not. But as a consequence of having a single BGP peering (against the route server), the BGP speakers can no longer distinguish from/to which peer each announce comes/goes.
This means that the routers connected to the route server are not able to apply by themselves the same input/output filters as in the full mesh scenario, so they have to delegate those functions to the route server.
Even more, the 'best path' selection must be also performed inside the route server on behalf of its clients. The reason is that if, after applying the filters of the announcer and the (potential) receiver, the route server decides to send to some client two or more different announcements referred to the same destination, the client will only retain the last one, considering it as an implicit withdrawal of the previous announcements for the same destination. This is the expected behavior of a BGP speaker as defined in RFC 1771, and even though there are some proposals of mechanisms that permit multiple paths for the same destination to be sent through a single BGP peering, none are currently supported by most existing BGP implementations.
As a consequence a route server must maintain additional information and perform additional tasks for a RS-client that those necessary for common BGP peerings. Essentially a route server must:
- Maintain a separated Routing Information Base (Loc-RIB) for each peer configured as RS-client, containing the routes selected as a result of the 'Best Path Selection' process that is performed on behalf of that RS-client.
- Whenever it receives an announcement from a RS-client,
it must consider it for the Loc-RIBs of the other RS-clients.
- This means that for each of them the route server must pass the announcement through the appropriate Out filter of the announcer.
- Then through the appropriate In filter of the potential receiver.
- Only if the announcement is accepted by both filters it will be passed to the 'Best Path Selection' process.
- Finally, it might go into the Loc-RIB of the receiver.
When we talk about the 'appropriate' filter, both the announcer and the receiver of the route must be taken into account. Suppose that the route server receives an announcement from client A, and the route server is considering it for the Loc-RIB of client B. The filters that should be applied are the same that would be used in the full mesh scenario, i.e., first the Out filter of router A for announcements going to router B, and then the In filter of router B for announcements coming from router A.
We call 'Export Policy' of a RS-client to the set of Out filters that the client would use if there was no route server. The same applies for the 'Import Policy' of a RS-client and the set of In filters of the client if there was no route server.
It is also common to demand from a route server that it does not modify some BGP attributes (next-hop, as-path and MED) that are usually modified by standard BGP speakers before announcing a route.
The announcement processing model implemented by FRR is shown in Announcement processing model implemented by the Route Server. The figure shows a mixture of RS-clients (B, C and D) with normal BGP peers (A). There are some details that worth additional comments:
- Announcements coming from a normal BGP peer are also considered for the Loc-RIBs of all the RS-clients. But logically they do not pass through any export policy.
- Those peers that are configured as RS-clients do not receive any announce from the Main Loc-RIB.
- Apart from import and export policies, In and Out filters can also be set for RS-clients. In filters might be useful when the route server has also normal BGP peers. On the other hand, Out filters for RS-clients are probably unnecessary, but we decided not to remove them as they do not hurt anybody (they can always be left empty).
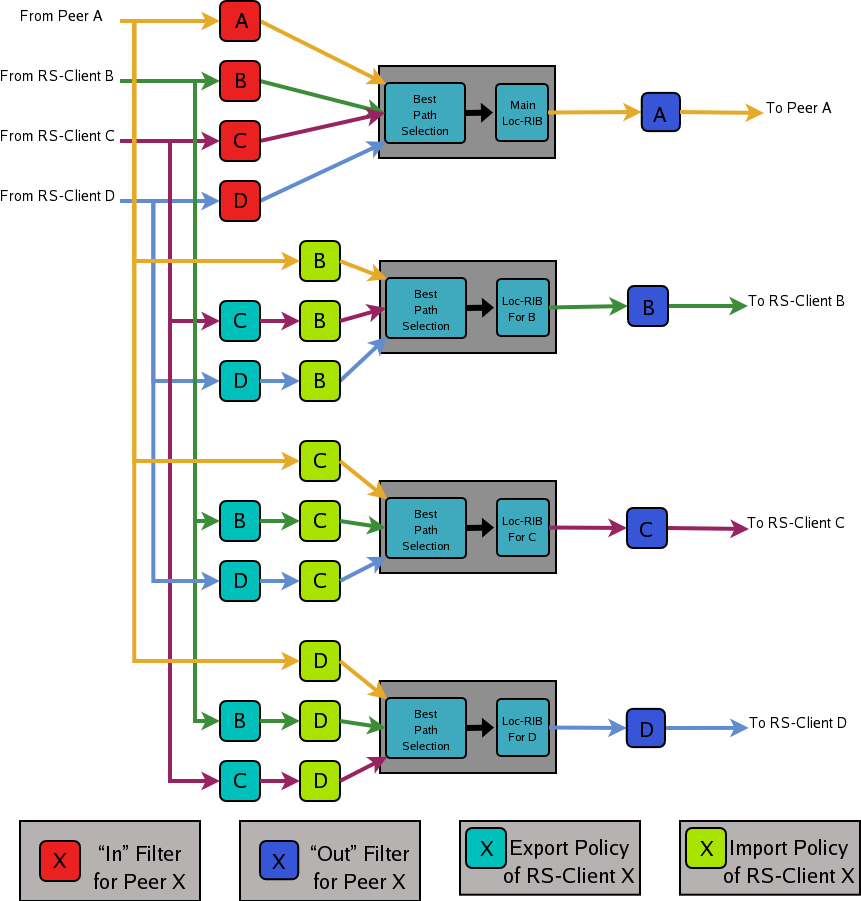
Announcement processing model implemented by the Route Server
Commands for configuring a Route Server¶
Now we will describe the commands that have been added to frr in order to support the route server features.
-
neighbor PEER-GROUP route-server-client¶
-
neighbor A.B.C.D route-server-client¶
-
neighbor X:X::X:X route-server-client¶ This command configures the peer given by peer, A.B.C.D or X:X::X:X as an RS-client.
Actually this command is not new, it already existed in standard FRR. It enables the transparent mode for the specified peer. This means that some BGP attributes (as-path, next-hop and MED) of the routes announced to that peer are not modified.
With the route server patch, this command, apart from setting the transparent mode, creates a new Loc-RIB dedicated to the specified peer (those named Loc-RIB for X in Announcement processing model implemented by the Route Server.). Starting from that moment, every announcement received by the route server will be also considered for the new Loc-RIB.
-
neigbor A.B.C.D|X.X::X.X|peer-group route-map WORD import|export¶ This set of commands can be used to specify the route-map that represents the Import or Export policy of a peer which is configured as a RS-client (with the previous command).
-
match peer A.B.C.D|X:X::X:X¶ This is a new match statement for use in route-maps, enabling them to describe import/export policies. As we said before, an import/export policy represents a set of input/output filters of the RS-client. This statement makes possible that a single route-map represents the full set of filters that a BGP speaker would use for its different peers in a non-RS scenario.
The match peer statement has different semantics whether it is used inside an import or an export route-map. In the first case the statement matches if the address of the peer who sends the announce is the same that the address specified by {A.B.C.D|X:X::X:X}. For export route-maps it matches when {A.B.C.D|X:X::X:X} is the address of the RS-Client into whose Loc-RIB the announce is going to be inserted (how the same export policy is applied before different Loc-RIBs is shown in Announcement processing model implemented by the Route Server.).
-
call WORD¶ This command (also used inside a route-map) jumps into a different route-map, whose name is specified by WORD. When the called route-map finishes, depending on its result the original route-map continues or not. Apart from being useful for making import/export route-maps easier to write, this command can also be used inside any normal (in or out) route-map.
Example of Route Server Configuration¶
Finally we are going to show how to configure a FRR daemon to act as a Route Server. For this purpose we are going to present a scenario without route server, and then we will show how to use the configurations of the BGP routers to generate the configuration of the route server.
All the configuration files shown in this section have been taken from scenarios which were tested using the VNUML tool http://www.dit.upm.es/vnuml,VNUML.
Configuration of the BGP routers without Route Server¶
We will suppose that our initial scenario is an exchange point with three BGP capable routers, named RA, RB and RC. Each of the BGP speakers generates some routes (with the network command), and establishes BGP peerings against the other two routers. These peerings have In and Out route-maps configured, named like 'PEER-X-IN' or 'PEER-X-OUT'. For example the configuration file for router RA could be the following:
#Configuration for router 'RA'
!
hostname RA
password ****
!
router bgp 65001
no bgp default ipv4-unicast
neighbor 2001:0DB8::B remote-as 65002
neighbor 2001:0DB8::C remote-as 65003
!
address-family ipv6
network 2001:0DB8:AAAA:1::/64
network 2001:0DB8:AAAA:2::/64
network 2001:0DB8:0000:1::/64
network 2001:0DB8:0000:2::/64
neighbor 2001:0DB8::B activate
neighbor 2001:0DB8::B soft-reconfiguration inbound
neighbor 2001:0DB8::B route-map PEER-B-IN in
neighbor 2001:0DB8::B route-map PEER-B-OUT out
neighbor 2001:0DB8::C activate
neighbor 2001:0DB8::C soft-reconfiguration inbound
neighbor 2001:0DB8::C route-map PEER-C-IN in
neighbor 2001:0DB8::C route-map PEER-C-OUT out
exit-address-family
!
ipv6 prefix-list COMMON-PREFIXES seq 5 permit 2001:0DB8:0000::/48 ge 64 le 64
ipv6 prefix-list COMMON-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-A-PREFIXES seq 5 permit 2001:0DB8:AAAA::/48 ge 64 le 64
ipv6 prefix-list PEER-A-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-B-PREFIXES seq 5 permit 2001:0DB8:BBBB::/48 ge 64 le 64
ipv6 prefix-list PEER-B-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-C-PREFIXES seq 5 permit 2001:0DB8:CCCC::/48 ge 64 le 64
ipv6 prefix-list PEER-C-PREFIXES seq 10 deny any
!
route-map PEER-B-IN permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set metric 100
route-map PEER-B-IN permit 20
match ipv6 address prefix-list PEER-B-PREFIXES
set community 65001:11111
!
route-map PEER-C-IN permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set metric 200
route-map PEER-C-IN permit 20
match ipv6 address prefix-list PEER-C-PREFIXES
set community 65001:22222
!
route-map PEER-B-OUT permit 10
match ipv6 address prefix-list PEER-A-PREFIXES
!
route-map PEER-C-OUT permit 10
match ipv6 address prefix-list PEER-A-PREFIXES
!
line vty
!
Configuration of the BGP routers with Route Server¶
To convert the initial scenario into one with route server, first we must modify the configuration of routers RA, RB and RC. Now they must not peer between them, but only with the route server. For example, RA's configuration would turn into:
# Configuration for router 'RA'
!
hostname RA
password ****
!
router bgp 65001
no bgp default ipv4-unicast
neighbor 2001:0DB8::FFFF remote-as 65000
!
address-family ipv6
network 2001:0DB8:AAAA:1::/64
network 2001:0DB8:AAAA:2::/64
network 2001:0DB8:0000:1::/64
network 2001:0DB8:0000:2::/64
neighbor 2001:0DB8::FFFF activate
neighbor 2001:0DB8::FFFF soft-reconfiguration inbound
exit-address-family
!
line vty
!
Which is logically much simpler than its initial configuration, as it now maintains only one BGP peering and all the filters (route-maps) have disappeared.
Configuration of the Route Server itself¶
As we said when we described the functions of a route server (Description of the Route Server model), it is in charge of all the route filtering. To achieve that, the In and Out filters from the RA, RB and RC configurations must be converted into Import and Export policies in the route server.
This is a fragment of the route server configuration (we only show the policies for client RA):
# Configuration for Route Server ('RS')
!
hostname RS
password ix
!
router bgp 65000 view RS
no bgp default ipv4-unicast
neighbor 2001:0DB8::A remote-as 65001
neighbor 2001:0DB8::B remote-as 65002
neighbor 2001:0DB8::C remote-as 65003
!
address-family ipv6
neighbor 2001:0DB8::A activate
neighbor 2001:0DB8::A route-server-client
neighbor 2001:0DB8::A route-map RSCLIENT-A-IMPORT import
neighbor 2001:0DB8::A route-map RSCLIENT-A-EXPORT export
neighbor 2001:0DB8::A soft-reconfiguration inbound
neighbor 2001:0DB8::B activate
neighbor 2001:0DB8::B route-server-client
neighbor 2001:0DB8::B route-map RSCLIENT-B-IMPORT import
neighbor 2001:0DB8::B route-map RSCLIENT-B-EXPORT export
neighbor 2001:0DB8::B soft-reconfiguration inbound
neighbor 2001:0DB8::C activate
neighbor 2001:0DB8::C route-server-client
neighbor 2001:0DB8::C route-map RSCLIENT-C-IMPORT import
neighbor 2001:0DB8::C route-map RSCLIENT-C-EXPORT export
neighbor 2001:0DB8::C soft-reconfiguration inbound
exit-address-family
!
ipv6 prefix-list COMMON-PREFIXES seq 5 permit 2001:0DB8:0000::/48 ge 64 le 64
ipv6 prefix-list COMMON-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-A-PREFIXES seq 5 permit 2001:0DB8:AAAA::/48 ge 64 le 64
ipv6 prefix-list PEER-A-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-B-PREFIXES seq 5 permit 2001:0DB8:BBBB::/48 ge 64 le 64
ipv6 prefix-list PEER-B-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-C-PREFIXES seq 5 permit 2001:0DB8:CCCC::/48 ge 64 le 64
ipv6 prefix-list PEER-C-PREFIXES seq 10 deny any
!
route-map RSCLIENT-A-IMPORT permit 10
match peer 2001:0DB8::B
call A-IMPORT-FROM-B
route-map RSCLIENT-A-IMPORT permit 20
match peer 2001:0DB8::C
call A-IMPORT-FROM-C
!
route-map A-IMPORT-FROM-B permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set metric 100
route-map A-IMPORT-FROM-B permit 20
match ipv6 address prefix-list PEER-B-PREFIXES
set community 65001:11111
!
route-map A-IMPORT-FROM-C permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set metric 200
route-map A-IMPORT-FROM-C permit 20
match ipv6 address prefix-list PEER-C-PREFIXES
set community 65001:22222
!
route-map RSCLIENT-A-EXPORT permit 10
match peer 2001:0DB8::B
match ipv6 address prefix-list PEER-A-PREFIXES
route-map RSCLIENT-A-EXPORT permit 20
match peer 2001:0DB8::C
match ipv6 address prefix-list PEER-A-PREFIXES
!
...
...
...
If you compare the initial configuration of RA with the route server configuration above, you can see how easy it is to generate the Import and Export policies for RA from the In and Out route-maps of RA's original configuration.
When there was no route server, RA maintained two peerings, one with RB and another with RC. Each of this peerings had an In route-map configured. To build the Import route-map for client RA in the route server, simply add route-map entries following this scheme:
route-map <NAME> permit 10
match peer <Peer Address>
call <In Route-Map for this Peer>
route-map <NAME> permit 20
match peer <Another Peer Address>
call <In Route-Map for this Peer>
This is exactly the process that has been followed to generate the route-map RSCLIENT-A-IMPORT. The route-maps that are called inside it (A-IMPORT-FROM-B and A-IMPORT-FROM-C) are exactly the same than the In route-maps from the original configuration of RA (PEER-B-IN and PEER-C-IN), only the name is different.
The same could have been done to create the Export policy for RA (route-map RSCLIENT-A-EXPORT), but in this case the original Out route-maps where so simple that we decided not to use the call WORD commands, and we integrated all in a single route-map (RSCLIENT-A-EXPORT).
The Import and Export policies for RB and RC are not shown, but the process would be identical.
Further considerations about Import and Export route-maps¶
The current version of the route server patch only allows to specify a route-map for import and export policies, while in a standard BGP speaker apart from route-maps there are other tools for performing input and output filtering (access-lists, community-lists, ...). But this does not represent any limitation, as all kinds of filters can be included in import/export route-maps. For example suppose that in the non-route-server scenario peer RA had the following filters configured for input from peer B:
neighbor 2001:0DB8::B prefix-list LIST-1 in
neighbor 2001:0DB8::B filter-list LIST-2 in
neighbor 2001:0DB8::B route-map PEER-B-IN in
...
...
route-map PEER-B-IN permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set local-preference 100
route-map PEER-B-IN permit 20
match ipv6 address prefix-list PEER-B-PREFIXES
set community 65001:11111
It is possible to write a single route-map which is equivalent to the three filters (the community-list, the prefix-list and the route-map). That route-map can then be used inside the Import policy in the route server. Lets see how to do it:
neighbor 2001:0DB8::A route-map RSCLIENT-A-IMPORT import
...
!
...
route-map RSCLIENT-A-IMPORT permit 10
match peer 2001:0DB8::B
call A-IMPORT-FROM-B
...
...
!
route-map A-IMPORT-FROM-B permit 1
match ipv6 address prefix-list LIST-1
match as-path LIST-2
on-match goto 10
route-map A-IMPORT-FROM-B deny 2
route-map A-IMPORT-FROM-B permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set local-preference 100
route-map A-IMPORT-FROM-B permit 20
match ipv6 address prefix-list PEER-B-PREFIXES
set community 65001:11111
!
...
...
The route-map A-IMPORT-FROM-B is equivalent to the three filters (LIST-1, LIST-2 and PEER-B-IN). The first entry of route-map A-IMPORT-FROM-B (sequence number 1) matches if and only if both the prefix-list LIST-1 and the filter-list LIST-2 match. If that happens, due to the 'on-match goto 10' statement the next route-map entry to be processed will be number 10, and as of that point route-map A-IMPORT-FROM-B is identical to PEER-B-IN. If the first entry does not match, on-match goto 10' will be ignored and the next processed entry will be number 2, which will deny the route.
Thus, the result is the same that with the three original filters, i.e., if either LIST-1 or LIST-2 rejects the route, it does not reach the route-map PEER-B-IN. In case both LIST-1 and LIST-2 accept the route, it passes to PEER-B-IN, which can reject, accept or modify the route.
Prefix Origin Validation Using RPKI¶
Prefix Origin Validation allows BGP routers to verify if the origin AS of an IP prefix is legitimate to announce this IP prefix. The required attestation objects are stored in the Resource Public Key Infrastructure (RPKI). However, RPKI-enabled routers do not store cryptographic data itself but only validation information. The validation of the cryptographic data (so called Route Origin Authorization, or short ROA, objects) will be performed by trusted cache servers. The RPKI/RTR protocol defines a standard mechanism to maintain the exchange of the prefix/origin AS mapping between the cache server and routers. In combination with a BGP Prefix Origin Validation scheme a router is able to verify received BGP updates without suffering from cryptographic complexity.
The RPKI/RTR protocol is defined in RFC 6810 and the validation scheme in RFC 6811. The current version of Prefix Origin Validation in FRR implements both RFCs.
For a more detailed but still easy-to-read background, we suggest:
Features of the Current Implementation¶
In a nutshell, the current implementation provides the following features
- The BGP router can connect to one or more RPKI cache servers to receive validated prefix to origin AS mappings. Advanced failover can be implemented by server sockets with different preference values.
- If no connection to an RPKI cache server can be established after a pre-defined timeout, the router will process routes without prefix origin validation. It still will try to establish a connection to an RPKI cache server in the background.
- By default, enabling RPKI does not change best path selection. In particular, invalid prefixes will still be considered during best path selection. However, the router can be configured to ignore all invalid prefixes.
- Route maps can be configured to match a specific RPKI validation state. This allows the creation of local policies, which handle BGP routes based on the outcome of the Prefix Origin Validation.
- Updates from the RPKI cache servers are directly applied and path selection is updated accordingly. (Soft reconfiguration must be enabled for this to work).
Enabling RPKI¶
-
rpki¶ This command enables the RPKI configuration mode. Most commands that start with rpki can only be used in this mode.
When it is used in a telnet session, leaving of this mode cause rpki to be initialized.
Executing this command alone does not activate prefix validation. You need to configure at least one reachable cache server. See section Configuring RPKI/RTR Cache Servers for configuring a cache server.
When first installing FRR with RPKI support from the pre-packaged binaries.
Remember to add -M rpki to the variable bgpd_options in
/etc/frr/daemons , like so:
bgpd_options=" -A 127.0.0.1 -M rpki"
instead of the default setting:
bgpd_options=" -A 127.0.0.1"
Otherwise you will encounter an error when trying to enter RPKI
configuration mode due to the rpki module not being loaded when the BGP
daemon is initialized.
Examples of the error:
router(config)# debug rpki
% [BGP] Unknown command: debug rpki
router(config)# rpki
% [BGP] Unknown command: rpki
Note that the RPKI commands will be available in vtysh when running
find rpki regardless of whether the module is loaded.
Configuring RPKI/RTR Cache Servers¶
The following commands are independent of a specific cache server.
-
rpki polling_period (1-3600)¶
-
no rpki polling_period¶ Set the number of seconds the router waits until the router asks the cache again for updated data.
The default value is 300 seconds.
The following commands configure one or multiple cache servers.
-
rpki cache (A.B.C.D|WORD) PORT [SSH_USERNAME] [SSH_PRIVKEY_PATH] [SSH_PUBKEY_PATH] [KNOWN_HOSTS_PATH] PREFERENCE¶
-
no rpki cache (A.B.C.D|WORD) [PORT] PREFERENCE¶ Add a cache server to the socket. By default, the connection between router and cache server is based on plain TCP. Protecting the connection between router and cache server by SSH is optional. Deleting a socket removes the associated cache server and terminates the existing connection.
- A.B.C.D|WORD
- Address of the cache server.
- PORT
- Port number to connect to the cache server
- SSH_USERNAME
- SSH username to establish an SSH connection to the cache server.
- SSH_PRIVKEY_PATH
- Local path that includes the private key file of the router.
- SSH_PUBKEY_PATH
- Local path that includes the public key file of the router.
- KNOWN_HOSTS_PATH
- Local path that includes the known hosts file. The default value depends
on the configuration of the operating system environment, usually
~/.ssh/known_hosts.
Validating BGP Updates¶
-
match rpki notfound|invalid|valid¶
-
no match rpki notfound|invalid|valid¶ Create a clause for a route map to match prefixes with the specified RPKI state.
In the following example, the router prefers valid routes over invalid prefixes because invalid routes have a lower local preference.
! Allow for invalid routes in route selection process route bgp 60001 ! ! Set local preference of invalid prefixes to 10 route-map rpki permit 10 match rpki invalid set local-preference 10 ! ! Set local preference of valid prefixes to 500 route-map rpki permit 500 match rpki valid set local-preference 500
Displaying RPKI¶
-
show rpki prefix-table¶ Display all validated prefix to origin AS mappings/records which have been received from the cache servers and stored in the router. Based on this data, the router validates BGP Updates.
-
show rpki cache-connection¶ Display all configured cache servers, whether active or not.
RPKI Configuration Example¶
hostname bgpd1
password zebra
! log stdout
debug bgp updates
debug bgp keepalives
debug rpki
!
rpki
rpki polling_period 1000
rpki timeout 10
! SSH Example:
rpki cache example.com 22 rtr-ssh ./ssh_key/id_rsa ./ssh_key/id_rsa.pub preference 1
! TCP Example:
rpki cache rpki-validator.realmv6.org 8282 preference 2
exit
!
router bgp 60001
bgp router-id 141.22.28.223
network 192.168.0.0/16
neighbor 123.123.123.0 remote-as 60002
neighbor 123.123.123.0 route-map rpki in
!
address-family ipv6
neighbor 123.123.123.0 activate
neighbor 123.123.123.0 route-map rpki in
exit-address-family
!
route-map rpki permit 10
match rpki invalid
set local-preference 10
!
route-map rpki permit 20
match rpki notfound
set local-preference 20
!
route-map rpki permit 30
match rpki valid
set local-preference 30
!
route-map rpki permit 40
!
| [Securing-BGP] | Geoff Huston, Randy Bush: Securing BGP, In: The Internet Protocol Journal, Volume 14, No. 2, 2011. <http://www.cisco.com/web/about/ac123/ac147/archived_issues/ipj_14-2/142_bgp.html> |
| [Resource-Certification] | Geoff Huston: Resource Certification, In: The Internet Protocol Journal, Volume 12, No.1, 2009. <http://www.cisco.com/web/about/ac123/ac147/archived_issues/ipj_12-1/121_resource.html> |
Flowspec¶
Overview¶
Flowspec introduces a new NLRI encoding format that is used to distribute traffic rule flow specifications. Basically, instead of simply relying on destination IP address for IP prefixes, the IP prefix is replaced by a n-tuple consisting of a rule. That rule can be a more or less complex combination of the following:
- Network source/destination (can be one or the other, or both).
- Layer 4 information for UDP/TCP: source port, destination port, or any port.
- Layer 4 information for ICMP type and ICMP code.
- Layer 4 information for TCP Flags.
- Layer 3 information: DSCP value, Protocol type, packet length, fragmentation.
- Misc layer 4 TCP flags.
A combination of the above rules is applied for traffic filtering. This is encoded as part of specific BGP extended communities and the action can range from the obvious rerouting (to nexthop or to separate VRF) to shaping, or discard.
The following IETF drafts and RFCs have been used to implement FRR Flowspec:
Design Principles¶
FRR implements the Flowspec client side, that is to say that BGP is able to receive Flowspec entries, but is not able to act as manager and send Flowspec entries.
Linux provides the following mechanisms to implement policy based routing:
- Filtering the traffic with
Netfilter.Netfilterprovides a set of tools likeipsetandiptablesthat are powerful enough to be able to filter such Flowspec filter rule. - using non standard routing tables via
iproute2(via theip rulecommand provided byiproute2).iproute2is already used by FRR's PBR daemon which provides basic policy based routing based on IP source and destination criterion.
Below example is an illustration of what Flowspec will inject in the underlying system:
# linux shell
ipset create match0x102 hash:net,net counters
ipset add match0x102 32.0.0.0/16,40.0.0.0/16
iptables -N match0x102 -t mangle
iptables -A match0x102 -t mangle -j MARK --set-mark 102
iptables -A match0x102 -t mangle -j ACCEPT
iptables -i ntfp3 -t mangle -I PREROUTING -m set --match-set match0x102
src,dst -g match0x102
ip rule add fwmark 102 lookup 102
ip route add 40.0.0.0/16 via 44.0.0.2 table 102
For handling an incoming Flowspec entry, the following workflow is applied:
- Incoming Flowspec entries are handled by bgpd, stored in the BGP RIB.
- Flowspec entry is installed according to its complexity.
It will be installed if one of the following filtering action is seen on the BGP extended community: either redirect IP, or redirect VRF, in conjunction with rate option, for redirecting traffic. Or rate option set to 0, for discarding traffic.
According to the degree of complexity of the Flowspec entry, it will be installed in zebra RIB. For more information about what is supported in the FRR implementation as rule, see Limitations / Known Issues chapter. Flowspec entry is split in several parts before being sent to zebra.
- zebra daemon receives the policy routing configuration
Policy Based Routing entities necessary to policy route the traffic in the
underlying system, are received by zebra. Two filtering contexts will be
created or appended in Netfilter: ipset and iptable context. The
former is used to define an IP filter based on multiple criterium. For
instance, an ipset net:net is based on two ip addresses, while
net,port,net is based on two ip addresses and one port (for ICMP, UDP, or
TCP). The way the filtering is used (for example, is src port or dst port
used?) is defined by the latter filtering context. iptable command will
reference the ipset context and will tell how to filter and what to do. In
our case, a marker will be set to indicate iproute2 where to forward the
traffic to. Sometimes, for dropping action, there is no need to add a marker;
the iptable will tell to drop all packets matching the ipset entry.
Configuration Guide¶
In order to configure an IPv4 Flowspec engine, use the following configuration. As of today, it is only possible to configure Flowspec on the default VRF.
router bgp <AS>
neighbor <A.B.C.D> remote-as <remoteAS>
address-family ipv4 flowspec
neighbor <A.B.C.D> activate
exit
exit
You can see Flowspec entries, by using one of the following show commands:
-
show bgp ipv4 flowspec [detail | A.B.C.D]¶
Per-interface configuration¶
One nice feature to use is the ability to apply Flowspec to a specific interface, instead of applying it to the whole machine. Despite the following IETF draft [Draft-IETF-IDR-Flowspec-Interface-Set] is not implemented, it is possible to manually limit Flowspec application to some incoming interfaces. Actually, not using it can result to some unexpected behaviour like accounting twice the traffic, or slow down the traffic (filtering costs). To limit Flowspec to one specific interface, use the following command, under flowspec address-family node.
-
[no] local-install <IFNAME | any>¶
By default, Flowspec is activated on all interfaces. Installing it to a named interface will result in allowing only this interface. Conversely, enabling any interface will flush all previously configured interfaces.
VRF redirection¶
Another nice feature to configure is the ability to redirect traffic to a separate VRF. This feature does not go against the ability to configure Flowspec only on default VRF. Actually, when you receive incoming BGP flowspec entries on that default VRF, you can redirect traffic to an other VRF.
As a reminder, BGP flowspec entries have a BGP extended community that contains a Route Target. Finding out a local VRF based on Route Target consists in the following:
- A configuration of each VRF must be done, with its Route Target set
Each VRF is being configured within a BGP VRF instance with its own Route
Target list. Route Target accepted format matches the following:
A.B.C.D:U16, orU16:U32,U32:U16. - The first VRF with the matching Route Target will be selected to route traffic to. Use the following command under ipv4 unicast address-family node
-
[no] rt redirect import RTLIST...¶
In order to illustrate, if the Route Target configured in the Flowspec entry is
E.F.G.H:II, then a BGP VRF instance with the same Route Target will be set
set. That VRF will then be selected. The below full configuration example
depicts how Route Targets are configured and how VRFs and cross VRF
configuration is done. Note that the VRF are mapped on Linux Network
Namespaces. For data traffic to cross VRF boundaries, virtual ethernet
interfaces are created with private IP addressing scheme.
router bgp <ASx>
neighbor <A.B.C.D> remote-as <ASz>
address-family ipv4 flowspec
neighbor A.B.C.D activate
exit
exit
router bgp <ASy> vrf vrf2
address-family ipv4 unicast
rt redirect import <E.F.G.H:II>
exit
exit
Flowspec monitoring & troubleshooting¶
You can monitor policy-routing objects by using one of the following commands.
Those command rely on the filtering contexts configured from BGP, and get the
statistics information retrieved from the underlying system. In other words,
those statistics are retrieved from Netfilter.
-
show pbr ipset IPSETNAME | iptable¶
IPSETNAME is the policy routing object name created by ipset. About
rule contexts, it is possible to know which rule has been configured to
policy-route some specific traffic. The show pbr iptable command
displays for forwarded traffic, which table is used. Then it is easy to use
that table identifier to dump the routing table that the forwarded traffic will
match.
-
show ip route table TABLEID¶ TABLEIDis the table number identifier referencing the non standard routing table used in this example.
-
[no] debug bgp flowspec¶ You can troubleshoot Flowspec, or BGP policy based routing. For instance, if you encounter some issues when decoding a Flowspec entry, you should enable
debug bgp flowspec.
-
[no] debug bgp pbr [error]¶ If you fail to apply the flowspec entry into zebra, there should be some relationship with policy routing mechanism. Here,
debug bgp pbr errorcould help.To get information about policy routing contexts created/removed, only use
debug bgp pbrcommand.
Ensuring that a Flowspec entry has been correctly installed and that incoming traffic is policy-routed correctly can be checked as demonstrated below. First of all, you must check whether the Flowspec entry has been installed or not.
CLI# show bgp ipv4 flowspec 5.5.5.2/32
BGP flowspec entry: (flags 0x418)
Destination Address 5.5.5.2/32
IP Protocol = 17
Destination Port >= 50 , <= 90
FS:redirect VRF RT:255.255.255.255:255
received for 18:41:37
installed in PBR (match0x271ce00)
This means that the Flowspec entry has been installed in an iptable named
match0x271ce00. Once you have confirmation it is installed, you can check
whether you find the associate entry by executing following command. You can
also check whether incoming traffic has been matched by looking at counter
line.
CLI# show pbr ipset match0x271ce00
IPset match0x271ce00 type net,port
to 5.5.5.0/24:proto 6:80-120 (8)
pkts 1000, bytes 1000000
to 5.5.5.2:proto 17:50-90 (5)
pkts 1692918, bytes 157441374
As you can see, the entry is present. note that an iptable entry can be
used to host several Flowspec entries. In order to know where the matching
traffic is redirected to, you have to look at the policy routing rules. The
policy-routing is done by forwarding traffic to a routing table number. That
routing table number is reached by using a iptable. The relationship
between the routing table number and the incoming traffic is a MARKER that
is set by the IPtable referencing the IPSet. In Flowspec case, iptable
referencing the ipset context have the same name. So it is easy to know
which routing table is used by issuing following command:
CLI# show pbr iptable
IPtable match0x271ce00 action redirect (5)
pkts 1700000, bytes 158000000
table 257, fwmark 257
...
As you can see, by using following Linux commands, the MARKER 0x101 is
present in both iptable and ip rule contexts.
# iptables -t mangle --list match0x271ce00 -v
Chain match0x271ce00 (1 references)
pkts bytes target prot opt in out source destination
1700K 158M MARK all -- any any anywhere anywhere
MARK set 0x101
1700K 158M ACCEPT all -- any any anywhere anywhere
# ip rule list
0:from all lookup local
0:from all fwmark 0x101 lookup 257
32766:from all lookup main
32767:from all lookup default
This allows us to see where the traffic is forwarded to.
Limitations / Known Issues¶
As you can see, Flowspec is rich and can be very complex. As of today, not all Flowspec rules will be able to be converted into Policy Based Routing actions.
The
Netfilterdriver is not integrated into FRR yet. Not having this piece of code prevents from injecting flowspec entries into the underlying system.There are some limitations around filtering contexts
If I take example of UDP ports, or TCP ports in Flowspec, the information can be a range of ports, or a unique value. This case is handled. However, complexity can be increased, if the flow is a combination of a list of range of ports and an enumerate of unique values. Here this case is not handled. Similarly, it is not possible to create a filter for both src port and dst port. For instance, filter on src port from [1-1000] and dst port = 80. The same kind of complexity is not possible for packet length, ICMP type, ICMP code.
There are some other known issues:
The validation procedure depicted in RFC 5575 is not available.
This validation procedure has not been implemented, as this feature was not used in the existing setups you shared with us.
The filtering action shaper value, if positive, is not used to apply shaping.
If value is positive, the traffic is redirected to the wished destination, without any other action configured by Flowspec. It is recommended to configure Quality of Service if needed, more globally on a per interface basis.
Upon an unexpected crash or other event, zebra may not have time to flush PBR contexts.
That is to say
ipset,iptableandip rulecontexts. This is also a consequence due to the fact that ip rule / ipset / iptables are not discovered at startup (not able to read appropriate contexts coming from Flowspec).
Appendix¶
More information with a public presentation that explains the design of Flowspec inside FRRouting.
| [Draft-IETF-IDR-Flowspec-redirect-IP] | <https://tools.ietf.org/id/draft-ietf-idr-flowspec-redirect-ip-02.txt> |
| [Draft-IETF-IDR-Flowspec-Interface-Set] | <https://tools.ietf.org/id/draft-ietf-idr-flowspec-interfaceset-03.txt> |
| [Presentation] | <https://docs.google.com/presentation/d/1ekQygUAG5yvQ3wWUyrw4Wcag0LgmbW1kV02IWcU4iUg/edit#slide=id.g378f0e1b5e_1_44> |
| [1] | For some set of objects to have an order, there must be some binary ordering relation that is defined for every combination of those objects, and that relation must be transitive. I.e.:, if the relation operator is <, and if a < b and b < c then that relation must carry over and it must be that a < c for the objects to have an order. The ordering relation may allow for equality, i.e. a < b and b < a may both be true and imply that a and b are equal in the order and not distinguished by it, in which case the set has a partial order. Otherwise, if there is an order, all the objects have a distinct place in the order and the set has a total order) |
| [bgp-route-osci-cond] | McPherson, D. and Gill, V. and Walton, D., "Border Gateway Protocol (BGP) Persistent Route Oscillation Condition", IETF RFC3345 |
| [stable-flexible-ibgp] | Flavel, A. and M. Roughan, "Stable and flexible iBGP", ACM SIGCOMM 2009 |
| [ibgp-correctness] | Griffin, T. and G. Wilfong, "On the correctness of IBGP configuration", ACM SIGCOMM 2002 |